
au sommaire


L’ADN est une molécule très longue, composée d’une succession de nucléotides accrochés les uns aux autres par des liaisons phosphodiester. C’est le support de l’information génétique. Son code, connu depuis plus de 50 ans, en cacherait un autre. © Spooky Pooka, Wellcome Images, cc by nc nd 2.0
Certaines recherches font plus de bruit que d'autres. La découverte de la structure de l’ADN (acide désoxyribonucléiqueacide désoxyribonucléique) par James Watson et Francis CrickFrancis Crick en 1953 en fait partie. Récompensée par le prix Nobel de médecine en 1962, elle a en effet complètement révolutionné les connaissances dans le domaine de la biologie.
La molécule d’ADN est en réalité connue depuis le début des années 1950. À cette époque, les biologistes savaient qu'elle était constituée de quatre types de moléculesmolécules plus petites, appelées nucléotides, se distinguant par leur base azotée : A (adénine), TT (thymine), C (cytosine) et G (guanine). Ce qu'ils ignoraient en revanche c'est comment l'ADN était structuré. James Watson et Francis Crick ont brillamment éclairci le mystère et ont montré que la molécule d'ADN possédait une structure en forme de double hélice au sein de laquelle les bases s'appariaient de façon spécifique, les A avec les T et les C avec les G.
, T (thymine), C (cytosine) et G (guanine), du nom des bases azotées correspondantes. Ces nucléotides se regroupent par paires spéciales : A avec T ; T avec A, C avec G et G avec C. © Dosto, Wikimedia Commons, cc by sa 2.5")
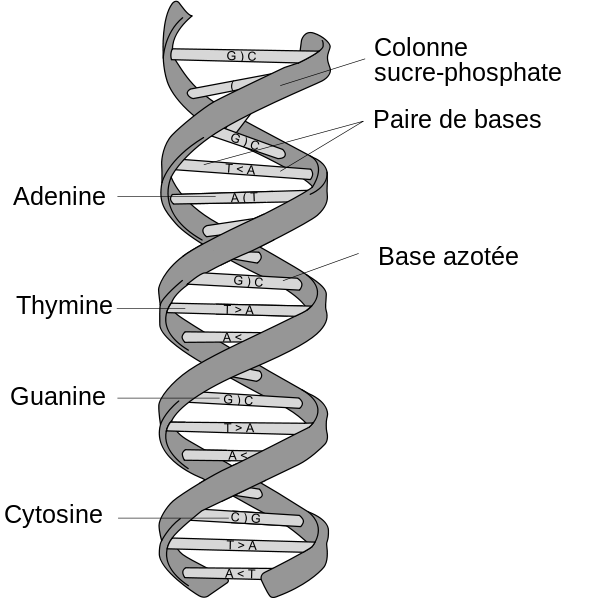
L'ADN est constitué de quatre nucléotides différents, notés A (adénine), T (thymine), C (cytosine) et G (guanine), du nom des bases azotées correspondantes. Ces nucléotides se regroupent par paires spéciales : A avec T ; T avec A, C avec G et G avec C. © Dosto, Wikimedia Commons, cc by sa 2.5
Grâce à ces données fondamentales, les scientifiques ont pu comprendre comment se transmettait l'information génétiquegénétique dans la cellule. Les chercheurs ont démontré que les nucléotidesnucléotides présents dans l'ADN étaient alignés de façon spécifique, formant un code permettant la production des acides aminésacides aminés et des protéinesprotéines. Trois nucléotides accolés constituent une sorte de mot, appelé codoncodon, qui est lu puis traduit en un des 20 acides aminés de la cellule. Les acides aminés sont alors ficelés les uns aux autres puis sont assemblés pour former une protéine. Dans certaines conditions, des mutations peuvent apparaître et modifier le code. La protéine mutée résultante peut perdre sa fonction, ce qui peut conduire au développement d'une pathologiepathologie.
De l’ADN à la régulation génétique
Depuis cette époque, de nombreux progrès ont été accomplis et les scientifiques peuvent désormais connaître très rapidement la séquence d'un gènegène d'intérêt. En avril 2003, le séquençage complet du génomegénome humain a été réalisé et les quelque 25.000 gènes identifiés sont désormais étudiés en détail à travers le globe. Les scientifiques ne sont cependant pas au bout de leur peine et l'ADN cache encore son lot de secrets. Récemment, une équipe a par exemple observé dans les cellules une forme particulière d'ADN, le G quadrupède ou ADN à quatre brins, qui n'avait jamais été identifiée jusque-là in vivoin vivo.
Au fur et à mesure des années, les chercheurs se sont rendu compte que la lecture de l'ADN était beaucoup plus complexe qu'ils ne pensaient au départ. Ils ont montré que le code génétique ne faisait pas tout mais que la façon dont il était lu était également primordiale. En d'autres termes, ce n'est pas seulement les phrases du livre qui comptent mais également la façon dont l'histoire est racontée. Les gènes peuvent ainsi être plus ou moins bien lus et conduire à une production plus au moins élevée de protéines. C'est ce qui explique pourquoi, au sein d'un même organisme, toutes les cellules ont le même génome mais ont pourtant des destins très différents : certaines deviennent des globules rougesglobules rouges, d'autres des cellules immunitaires, d'autres des neuronesneurones, etc. Ce mécanisme, appelé régulation génétique, est contrôlé par des composants cellulaires, les facteurs de régulation, qui peuvent se fixer sur des séquences spécifiques de l'ADN et moduler l'expression des gènes.
Un code peut en cacher un autre…
Dans le cadre du projet Encode (Encyclopedia of DNADNA elements)), qui vise à répertorier l'ensemble des séquences d'ADN du génome humain, des chercheurs de l'université de Washington (États-Unis) ont fait une découverte surprenante. Ils ont montré que le code génétiquecode génétique tel qu'on le connaissait jusqu'ici en cachait un autre, destiné quant à lui à la régulation de l'expression des gènes. Cette découverte est publiée dans la revue Science.
Le génome contient des séquences codantes et des séquences qui permettent aux facteurs de régulation de se fixer sur l'ADN pour contrôler l'expression des gènes. Grâce à des techniques de biologie moléculairebiologie moléculaire, les chercheurs ont analysé la répartition de ces deux types de séquences. Ils ont montré que 15 % des codons du génome humain avaient une double fonction : d'un côté ils participent à la fabrication des protéines, de l'autre ils donnent des instructions aux cellules pour moduler l'expression des différents gènes. Pour cette raison, les scientifiques les ont appelés « duons ».
« Le code génétique peut simultanément écrire deux sortes d'informations, explique John Stamatoyannopoulos, le directeur de l'étude. Il est donc possible que certaines mutations que l'on croyait uniquement liées à la séquence protéique, perturbent aussi le contrôle de l'expression des gènes. » Selon les auteurs, cette découverte pourrait permettre de mieux comprendre le développement de certaines maladies.

par Agnès Roux, Futura
le 17 décembre 2013
 a accepté de voir son génome décrypté. Il est aussi connu pour avoir tenu des propos très polémiques car racistes. Le biophysicien britannique Francis Crick (à droite) est quant à lui décédé le 28 juillet 2004. Il aurait lui aussi prononcé des paroles malvenues, montrant un intérêt marqué pour l'eugénisme. © Stan Honda et Daniel Mordzinski, AFP")


 fixés aux quatre coins d'une structure G-quadruplexe. © Jean-Paul Rodriguez")



















