

DeepMind, filiale de Google, a fait une nouvelle démonstration des performances de son programme d'intelligence artificielle. AlphaZero, une variante d'AlphaGo qui pratique l'apprentissage par renforcement, n'a mis que quatre heures en partant des règles de base pour vaincre le meilleur programme de jeux d'échecs actuel.
au sommaire
Après avoir démontré l'implacable supériorité de son intelligence artificielle (IA) au jeu de go, DeepMind, filiale de GoogleGoogle, cherche désormais à rendre celle-ci plus généraliste. L'objectif est de créer une IA réussissant à accomplir des tâches complexes dans le monde réel avec un minimum de connaissances a priori. Pour cela, il faut que le programme puisse évoluer de manière autonome sans s'appuyer sur un apprentissage supervisé par des humains.
Il y a peu, DeepMind a fait un pas important dans cette direction avec AlphaGoAlphaGo Zero, une nouvelle version de son programme de jeu de go qui n'a mis que trois jours à vaincre son prédécesseur en pratiquant un apprentissage « tabula rasa » par renforcement (reinforcement learning, en anglais). AlphaGo Zero ne disposait que des règles du jeu et de la position des pierres sur le plateau. Partant de cette base, elle est allée encore un peu plus loin.
Dans un nouvel article scientifique, DeepMind dévoile ainsi AlphaZero, qui reprend le principe de l'apprentissage autodidacte par renforcement dans une approche moins spécialisée. En disposant pour seule base des règles des jeux d’échecs, de go et de shogi (variante japonaise des échecs), cette IA est parvenue à atteindre un « niveau de jeu surhumain » et à battre les meilleurs programmes existant dans ces trois disciplines.


AlphaZero a battu Stockfish en quatre heures
La performance est d'autant plus impressionnante qu'il lui aura fallu moins de vingt-quatre heures pour y parvenir :
- Après huit heures d'entraînement et 21 millions de parties jouées contre lui-même, AlphaZero a battu AlphaGo-Lee, la première IA à avoir dominé un joueur humain.
- Pour les échecs, AlphaZero n'a eu besoin que de quatre heures de pratique et 44 millions de parties pour vaincre Stockfish, l'un des meilleurs moteurs d'échecs actuels.
- Deux heures et 24 millions de parties lui suffirent pour terrasser Elmo, le meilleur programme de shogi.
Cette polyvalence et cette rapiditérapidité rapprochent encore un peu plus DeepMind et Google de leur objectif : créer une intelligence artificielle généraliste susceptible de travailler dans des domaines concrets, notamment pour la science et la médecine. Google en retirerait aussi beaucoup d'avantages pour faire évoluer ses propres services. Le prochain grand défi pour DeepMind et sa maison mère sera de pouvoir battre les humains au jeu vidéo StarCraftStarCraft.
AlphaGo Zero : l'IA de Google DeepMind devient autodidacte
Article initial de Marc ZaffagniMarc Zaffagni, paru le 19/10/2017
AlphaGo Zero, une nouvelle version du programme de jeu de go de DeepMind, n'a mis que trois jours à vaincre son prédécesseur AlphaGo après s'être entrainé avec pour seules informations les règles du jeu et la position des pierres sur le plateau. Un pas de plus vers la création d'une intelligence artificielle généraliste.
« Maîtriser le jeu de Go sans connaissance humaine ». Tel est le titre de l'article publié dans la revue Nature par DeepMind qui résume le nouvel exploit accompli par la filiale d'Alphabet (maison-mère de Google) spécialisée dans l'intelligence artificielle (IA). Ses équipes ont créé une nouvelle version du logiciel AlphaGo qui a appris à jouer au go sans les moindres données ou connaissances humaines. AlphaGo Zero, c'est son nom, n'a eu à sa disposition que les règles de ce jeu millénaire et l'emplacement des pierres blanches et noires sur le plateau.
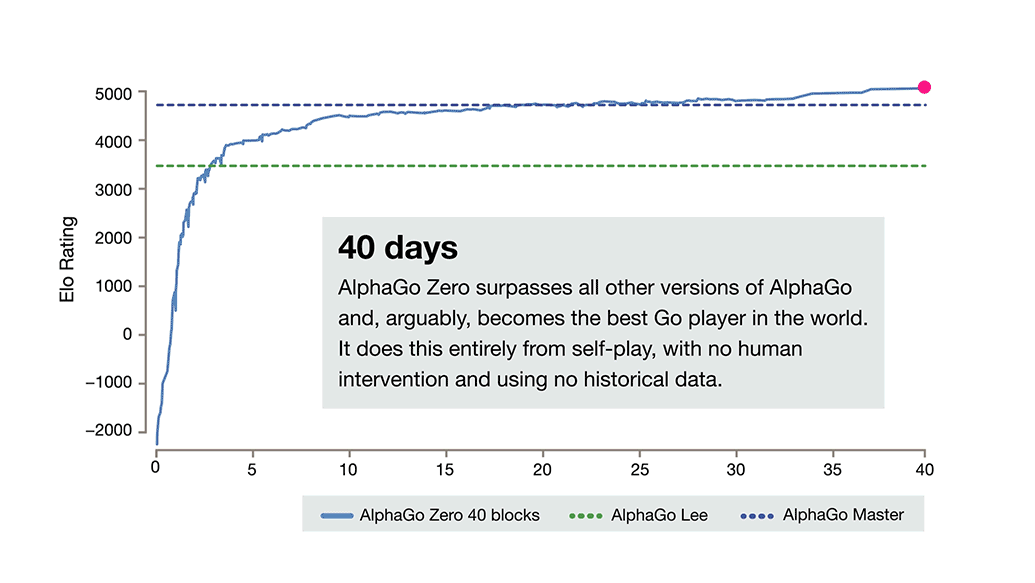
Partant de cette base, l'algorithme de recherche combiné à un réseau neuronal a joué des milliers de parties contre lui-même en améliorant sans cesse son niveau. Au bout de seulement trois jours, le programme a pulvérisé AlphaGo Lee, le logiciel qui avait battu le champion Lee Sedol, en gagnant 100 victoires à 0. Après 21 jours d'auto apprentissage, AlphaGo Zero était au niveau d'AlphaGo Master, la version qui a vaincu le numéro 1 mondial Ke Jie en mai dernier. Et 40 jours après le début de son entrainement, AlphaGo Zero a surpassé toutes les versions existantes pour devenir tour simplement le meilleur joueur de go de la planète.
Un apprentissage « tabula rasa »
La principale différence technique entre AlphaGo Zero et ses prédécesseurs est qu'il se base uniquement sur la technique d'apprentissage par renforcement (reinforcement learning). Les autres AlphaGo combinaient cette méthode avec de l'apprentissage supervisé alimenté par des parties de référence jouées par des humains.
Par ailleurs, AlphaGo Zero n'utilise plus qu'un seul réseau neuronal d'apprentissage profondapprentissage profond contre deux précédemment. Auparavant, les logiciels de DeepMind associaient un « réseau de décision » qui décidait du prochain mouvementmouvement à jouer à un « réseau de valeur » qui prédisait le vainqueur de la partie à partir des positions en cours sur le plateau. AlphaGo Zero a fusionné ces deux réseaux neuronaux pour gagner en efficacité et il n'a même plus besoin de jouer des parties aléatoires rapides pour prédire l'issue du jeu.
« Cette technique est plus puissante que les versions précédentes d'AlphaGo car elle n'est plus contrainte par les limites de la connaissance humaine. Au lieu de cela, elle est capable d'apprendre en partant d'une feuille blanche avec le joueur le plus fort du monde : AlphaGo lui-même », explique DeepMind sur son blog.

AlphaGo Zero a fait preuve de créativité
Non content d'être devenu imbattable en partant d'informations minimales, AlphaGo Zero a impressionné ses créateurs par sa capacité à s'approprier le jeu. Après avoir assimilé les bases et reproduit sans aide extérieure les stratégies de jeu élaborées par les humains depuis des milliers d'années, le programme est allé plus loin en créant des ouvertures totalement inédites. AlphaGo Zero a littéralement inventé de nouvelles formes de jeu, tout cela en l'espace de quelques jours.
Selon DeepMind, de telles capacités ouvrent des perspectives prometteuses pour la création d'IA capables de travailler dans des domaines concrets : santé, consommation d'énergieénergie, science des matériaux. « Vous avez un agent [une IA, NDLRNDLR] qui peut être transposé du jeu de go à n'importe quel autre domaine (...). Vous obtenez un algorithme qui devient si généraliste qu'il peut être appliqué n'importe où », estime David Silver, chercheur en chef sur AlphaGo.
Cependant, bien qu'il puisse évoluer en se passant de données humaines, un programme comme AlphaGo Zero a besoin de travailler sur un problème structuré avec des règles claires et un minimum d'imprévu. C'est la raison pour laquelle après le jeu de go, DeepMind a décidé de s'attaquer au jeu vidéo de stratégie Starcraft où la gestion de la part d'incertitude est beaucoup plus complexe. L'entreprise vise la même réussite qu'au jeu de go avec en arrière-plan la création d'une IA capable d'accomplir des tâches complexes dans le monde réel.
AlphaGo : après avoir battu le n° 1 mondial du jeu de go, l'IA prend sa retraite
Article initial de Marc Zaffagni, paru le 29/05/2017
AlphaGo a remporté ses trois matchs face au n° 1 mondial de jeu de go, Ke Jie. L'intelligence artificielle de DeepMind (Google) ne sera plus utilisée pour ce type d'exhibition. Elle va désormais servir à faire avancer la recherche scientifique et médicale.
Une intelligence artificielle (IA) a définitivement affirmé sa supériorité face à l'Homme au jeu de go. AlphaGo, le programme développé par DeepMind (filiale de Google), a gagné les trois manches l'opposant au numéro un mondial, le Chinois Ke Jie. Si Demis Hassabis, le fondateur et patron de DeepMind, a évité tout triomphalisme et salué le redoutable opposant d'AlphaGo, l'issue du combat ne laissait guère de doute.
En effet, depuis son apparition sur la scène médiatique à l'occasion de son affrontement contre les champions Fan Hui puis Lee Sedol, cette IA s'est constamment améliorée en jouant des millions de parties contre elle-même. Ce n'était donc qu'une question de temps et de puissance avant que la machine ne s'impose définitivement. En début d'année, AlphaGo avait déjà battu Ke Jie en jouant une série de matchs sur Internet affublé de pseudonymes. Cette nouvelle victoire « officielle » face au n° 1 mondial vient donc clore le débat sur la capacité d'une machine à maîtriser ce jeu millénaire qui fait la part belle à l'intuition.
N'ayant plus rien à prouver en matièrematière de jeu de go, AlphaGo va prendre sa retraite. DeepMind a en effet annoncé que cette compétition était la dernière pour son intelligence artificielle. « L'équipe de recherche derrière AlphaGo va maintenant consacrer son énergie à la prochaine série de grands défis, en développant des algorithmes généralistes avancés qui pourraient un jour aider les scientifiques à s'attaquer à certains de nos problèmes les plus complexes », peut-on lire dans le billet de blog publié par DeepMind.

Pour Google, AlphaGo n’est que le début d’un grand projet
Il est question d'utiliser la puissance d'AlphaGo pour aider à combattre certaines maladies, réduire la consommation d'énergie ou encore inventer de nouveaux matériaux. L'un des avantages majeurs de l'IA sur l'humain dans ce genre de projet ambitieux est sa capacité à brasser à grande vitesse des téraoctets de données hétérogènes et d'en extraire du sens. Les fondateurs de Google ne font pas mystère de leurs ambitions transhumanistes et voient l'intelligence artificielle comme un moyen d'augmenter les capacités humaines.
Lors de sa dernière conférence annuelleannuelle Google I/O, le géant californien a mis l'accent sur l'IA et le rôle toujours plus important qu'elle est amenée à jouer dans ses produits et services. Les travaux de DeepMind ainsi que la plateforme TensorFlow seront les fersfers de lance de cette stratégie.
Mais avant de passer à autre chose, l'équipe de DeepMind a choisi de faire quelques derniers cadeaux à la communauté du jeu de go. Tout d'abord, l'entreprise a publié cinquante parties jouées par AlphaGo contre elle-même pour s'entraîner. Ensuite, un article détaillant comment l'IA a été préparée pour affronter Ke Jie sera publié dans les prochains mois. Le champion chinois a également accepté de travailler avec DeepMind à l'élaboration d'un outil d'apprentissage qui montrera de quelle manière AlphaGo analyse les positions de jeu pour préparer ses coups.
Jeu de go : AlphaGo remporte son premier duel contre le n° 1 mondial
Article initial de Relaxnews, paru le 24/05/2017
À l'occasion du Sommet sur l'avenir du go qui se tient en Chine, l'IA AlphaGo de Google DeepMind s'est lancée dans une série de matchs qui le voit notamment affronter l'actuel numéro un mondial, le Chinois Ke Jie. Le premier duel a tourné à l'avantage de la machine, mais le combat fut serré.
Le superordinateursuperordinateur de Google a une nouvelle fois eu raison de l'être humain en battant mardi le petit génie chinois du go, millénaire jeu de stratégie asiatique. L'ordinateurordinateur AlphaGo a remporté la première de trois parties (voir le résumé sur YouTube) face au numéro un mondial Ke Jie, 19 ans, qui s'était un peu rapidement fait fort de vaincre « une machine sans âme ». L'intelligence artificielle a eu le dessus, mais de peu, s'imposant avec seulement un demi-point d'avance.
AlphaGo, mis au point par DeepMind Technologies, une filiale de Google spécialisée dans l'intelligence artificielle et basée à Londres, avait déjà fait sensation l'an dernier en battant le grand maître sud-coréen Lee Se-Dol par quatre parties à une. C'était la première fois qu'un logiciel écrasait un joueur chevronné lors d'un match entier.
La victoire d'AlphaGo avait été saluée comme une percée technologique pour les ordinateurs, désormais capables non seulement de conduire des voituresvoitures mais aussi d'aider l'humanité à résoudre quelques-uns des problèmes scientifiques, techniques ou médicaux les plus ardus. AlphaGo est ainsi doté d'algorithmes qui lui permettent d'apprendre de ses expériences.

Encore deux matchs à venir entre Ke Jie et AlphaGo
Le jeune Ke Jie, qui se décrit lui-même comme « prétentieux », avait alors relevé le défi. Mais il avait déjà dû en rabattre en début d'année après avoir été vaincu lors d'un match en ligne par un mystérieux adversaire -- on avait appris plus tard qu'il s'agissait d'AlphaGo. Avant le match de ce mardi à Wuzhen (est de la Chine), le joueur, champion du monde depuis plus de deux ans, avait assuré qu'il s'agirait de son dernier affrontement face à AlphaGo, qu'il gagne ou qu'il perde.
Déjà en 1997, le champion du monde d'échecs Garry Kasparov avait été vaincu par l'ordinateur Deep Blue d'IBM. Mais le défi pour la machine semblait bien plus relevé au jeu de go, dans lequel deux adversaires tentent d'occuper le plus d'espace sur un plateau quadrillé en plaçant alternativement des pierres noires et blanches.
La taille du tablier (19 lignes sur 19) offre un nombre incalculable de configurations possibles -- davantage qu'il n'y a d'atomesatomes dans l'universunivers -- et le déroulement du jeu obéit à des concepts stratégiques qui vont au-delà du simple calcul mathématique, aussi puissant soit-il. Ce qui signifie que l'intuition et la créativité sont essentielles pour gagner à très haut niveau. Deux domaines dans lesquels l'humain, croyait-on, était nécessairement supérieur à la machine. Kie Jie et AlphaGo s'affronteront encore deux fois, jeudi et samedi prochain. Les matchs commenceront à 4 h 30 du matin en France et les plus matinaux pourront les suivre en direct via la chaîne YouTubeYouTube de DeepMind.
Une nouvelle version d'AlphaGo a battu le n° 1 mondial
Article initial de Marc Zaffagni, paru le 14/01/2017
DeepMind, la filiale de Google, a testé en toute discrétion une nouvelle version de son IA de jeu de go. Sous les pseudonymes de « Master (P) » et « Magister (P) », AlphaGo a affronté de grands champions sur deux plateformes de jeu en ligne et remporté plus de 50 parties. Le programme a même battu le numéro un mondial, le Chinois Ke Jie.
Dans la foulée de la retentissante victoire de son intelligence artificielle AlphaGo contre le champion sud-coréen Lee Sedol, Demis Hassabis, le patron de DeepMind (filiale de Google spécialisée en IA) avait évoqué la possibilité d'affronter l'actuel numéro un mondial de jeu de go, le Chinois Ke Jie. Bien qu'aucune rencontre officielle n'ait encore été programmée, AlphaGo a d'ores et déjà vaincu ce jeune prodige de 19 ans... sans qu'il s'en soit rendu compte.
DeepMind vient en effet de révéler par la voix de Demis Hassabis qu'il avait discrètement testé une nouvelle version de son IA sur Tygem et FoxGo, deux serveursserveurs de jeu de go fréquentés par les plus grands champions. Pour passer inaperçu, AlphaGo a été affublé de deux pseudonymes, « Master (P) » et « Magister (P) ». L'IA a joué entre le 29 décembre et le 4 janvier et remporté plus de 50 parties de rang.
AlphaGo devrait affronter un nouveau champion de go cette année
À son tableau de chasse, outre Ke Jie, figurent d'autres grands noms du go comme Park Jung-hwan (Corée du Sud), Gu Li (Chine) et Iyama Yuta (Japon). Un résultat impressionnant qui est tout de même à relativiser dans la mesure où les parties en ligne étaient jouées en mode accéléré qui est considéré comme plus favorable à la machine.
Demis Hassabis a d'ailleurs indiqué que cette nouvelle mouture d'AlphaGo serait amenée à jouer des parties classiques de longue duréedurée et de manière officielle dans le courant de l'année. Reste à savoir quel grand champion de go acceptera de se frotter à cette IA qui semble désormais quasi impossible à battre...
Jeu de go : l’intelligence artificielle de Google bat l’humain
Article de Marc Zaffagni, paru le 28/01/2016
AplhaGo, programme d'intelligence artificielle développé par DeepMind, filiale de Google, a battu un joueur professionnel au jeu de go. Une avancée majeure qui n'était pas attendue avant une dizaine d'années. L'annonce vient d'en être faite, au moment d'une publication scientifique. De quoi décrypter la réalisation et la méthode, avec réseaux neuronaux et apprentissage. Accrochez vos ceintures et plongez avec nous dans les rouages d'AlphaGo qui défiera le champion du monde en mars prochain, et qui aura aussi, sans doute, des déclinaisonsdéclinaisons au-delà du jeu...
Cette semaine peut être considérée comme historique pour l'intelligence artificielle. D'une part, elle a perdu l'un de ses pères, Marvin Minsky et, d'autre part, elle a franchi une étape majeure dans son perfectionnement. Google a en effet annoncé que sa filiale DeepMind avait développé une intelligence artificielle qui a battu à plate couture un joueur professionnel. Nommé AlphaGo, le programme a surclassé Fan Hui, triple champion européen en titre du jeu de go, en gagnant cinq victoires à zéro. L'affrontement a eu lieu en octobre dernier, mais Google a souhaité attendre la parution de l'article scientifique consacré à ce défi dans la revue Nature avant d'annoncer cet exploit.
Pourquoi cette victoire est-elle si importante ? Parce que, après le succès de l'ordinateur Deep Blue face au champion du monde d'échecs Gary Kasparov en 1997, le go restait le seul jeu de réflexion à résister aux machines. Il y a un peu plus d'un an, les experts ayant développé les programmes de jeu de go les plus performants, à l'instar de Crazy Stone du Français Rémi Coulom, estimaient qu'il faudrait encore une décennie, voire plus, avant qu'une machine ne puisse vaincre un humain.
Les règles du go sont simples : deux joueurs s'affrontent sur un plateau où ils placent des pierres noires et blanches afin de délimiter des territoires et de capturer les pièces de l'adversaire. Le but ultime est de contrôler plus de la moitié du plateau. Mais cette apparente simplicité cache une profonde complexité car ce jeu repose avant tout sur l'intuition. « Le nombre de combinaisons possibles est supérieur au nombre d'atomes que compte l'univers », résume Demis Hassabis, l'un des fondateurs de la société britannique DeepMind que Google a acquise en 2014. Les techniques d'intelligence artificielle basées sur la force bruteforce brute, qui construisent un arbrearbre binairebinaire de recherche pour tester toutes les possibilités de mouvements, n'avaient jusqu'ici aucune chance de succès avec le jeu de go.
L’algorithme apprend en jouant contre lui-même
Pour réussir ce coup de maître, DeepMind a combiné les meilleurs techniques d'intelligence artificielle et la puissance de calcul mise à sa disposition par la plateforme de cloud computingcloud computing de Google. Au cœur du dispositif, deux réseaux neuronaux d'apprentissage profond ayant chacun une tâche différente. Le premier appelé policy network (quelque chose comme « réseau politique » ou « réseau de décision ») travaille à prédire le prochain coup tandis que le second, value network (« réseau de valeur »), estime l'issue favorable d'un mouvement à partir de la configuration du plateau de jeu.
Les deux réseaux ont été associés à un arbre binaire de recherche qui utilise la méthode algorithmiquealgorithmique probabiliste dite de Monte-Carlo sur laquelle reposent les logiciels de jeu de go les plus performants du moment (Crazy Stone et Zen). Elle consiste à jouer toutes les fins de parties possibles à partir d'une position en comptabilisant les parties gagnantes et perdantes. Les réseaux neuronaux sont là pour affiner la recherche, réduire sa complexité et sa profondeur, en adoptant une forme de raisonnement plus proche de l'imagination humaine.
Chaque réseau est composé de douze couches contenant chacune des millions de connexions neuronales. Les « réseaux politiques » ont été entraînés avec une base de donnéesbase de données de 30 millions de coups provenant de parties jouées par des experts jusqu'à ce qu'ils puissent prédire un mouvement 57 % du temps. Mais pour qu'AlphaGo puisse développer ses propres stratégies de jeu, DeepMind a eu recours à un apprentissage renforcé en lui faisant jouer des milliers de parties contre lui-même. Puis, les « réseaux politiques » ont été utilisés pour entraîner les « réseaux de valeur », toujours par apprentissage renforcé. « Ces réseaux de valeur peuvent évaluer n'importe quelle position de go et estimer l'éventuel gagnant », souligne Google.
Évidemment, cet ambitieux programme n'aurait pu aboutir sans la puissance de calcul et la capacité de stockage que le géant nord-américain a fourni à travers son réseau de cloud computing. Par ailleurs, l'équipe de DeepMind a utilisé la plateforme d'intelligence TensorFlow dont Google a récemment libéré le code sourcecode source. Ne restait plus ensuite qu'à envoyer AlphaGo défier un joueur professionnel. Mais avant cela, en guise d'échauffement si l'on peut dire, il a été confronté aux meilleurs logiciels de go du moment. Installé sur une seule machine, AlphaGo a remporté 499 des 500 parties disputées.


Comment sera utilisée cette intelligence artificielle ?
Face à Fan Hui, joueur français d'origine chinoise champion d'Europe en titre, le programme de DeepMind n'a pas fait de détails, s'adjugeant cinq victoires contre zéro pour son opposant. « Avec AlphaGo, on a joué durant cinq jours, avec deux parties par jour, une normale et une rapide. J'ai perdu 5-0 les parties normales, 3-2 les parties rapides. Comme lui joue très vite, j'aurais dû perdre plus dans les parties rapides, mais ce fut l'inverse, explique Fan Hui dans un entretien avec Le Monde. Je n'ai pas du tout eu l'impression de jouer contre un ordinateur. Il joue comme un humain ». Sans doute le meilleur compliment que pouvait recevoir AlphaGo...
Mais Google ne compte pas en rester là. Le prochain défi pour son intelligence artificielle sera de tenter de battre le champion du monde de la discipline, Lee Sedol. La rencontre aura lieu en mars prochain à Séoul et le match sera retransmis en direct via la chaîne YouTube DeepMind. « J'aurai le privilège d'affronter pour la première fois un ordinateur. J'ai entendu dire qu'AlphaGo est étonnamment fort et s'améliorera encore, mais je suis confiant que je pourrai gagner, au moins cette fois-ci », a déclaré Lee Sedol.
Quelle que soit l'issue de cet affrontement ultime, AlphaGo a d'ores et déjà fait accomplir un pas de géant à l'intelligence artificielle. Mais au-delà du jeu de go, la grande question est de savoir ce que Google compte faire de ce formidable outil. « Même si les jeux sont la plateforme idéale pour développer et tester rapidement des algorithmes d'intelligence artificielle, au bout du compte, nous voulons appliquer ces techniques à d'importants problèmes du monde réel », commente l'entreprise qui cite comme exemple la modélisationmodélisation climatique et le diagnosticdiagnostic de maladies complexes. On peut aussi penser que Google exploitera cette technologie pour perfectionner ses propres services, notamment son moteur de recherche et son assistant vocalassistant vocal pour smartphones.
Au cours de la conférence de presse qui a suivi la présentation d'AlphaGo, Demis Hassabis a été questionné sur les risques potentiels à long terme d'une intelligence artificielle aussi performante. Il a répondu que son entreprise collaborait sur ce sujet avec des universitaires, organisait des conférences et s'était dotée d'un comité d'éthique interne. « Par ailleurs, nous nous sommes mis d'accord avec Google pour que ces technologies ne soient pas utilisées à des fins militaires », a-t-il assuré.
Code Promo Cdiscount
Ce qu’il faut
retenir
- Le nouveau programme d’intelligence artificielle (IA) AlphaZero, de DeepMind, est capable d’apprendre par lui-même trois jeux de plateau différents sans utiliser de données humaines.
- Cette IA polyvalente n'a mis que quelques heures pour battre les meilleurs logiciels d'échecs et de shogi.










 ? © phonlamaiphoto, Adobe Stock")



, révèle la morphologie ultrastructurale des coronavirus. Notez les pointes, des protéines qui ornent la surface externe du virus donnant l'apparence d'une couronne entourant le virion, lorsqu'elles sont vues au microscope électronique. Un nouveau coronavirus, appelé syndrome respiratoire aigu sévère coronavirus 2 (SRAS-CoV-2), a été identifié comme la cause d'une épidémie de maladie respiratoire détectée pour la première fois à Wuhan, en Chine en 2019. La maladie causée par ce virus a été appelée maladie de coronavirus 2019 (Covid-19). © DP, Alissa Eckert, MS ; Dan Higgins, MAMS")


")






