

Le Web est un réservoir d’information sans égal. Encore faut-il savoir en extraire la « substantifique moelle » pour opérer des statistiques, repérer des tendances... Cette discipline s’appelle le « Web scraping » ou extraction de données. Elle est relativement complexe mais peut être maîtrisée par un data scientist formé à un outil tel que Beautiful Soup sous Python. Un parcours du combattant ? Il reste que le jeu en vaut la chandelle…
au sommaire
Internet est une source d’information considérable. Une analyse pointue des données du Web est en mesure de faire apparaître énormément d’informations utiles : tendances, évolutions des goûts du public, prix moyen d’un produit donné…
Imaginons que vous souhaitiez récupérer des informations de prix et d’évaluation sur un énorme site marchand. Qu’allez-vous faire ? Vous pouvez, bien évidemment demander à un stagiaire de consulter les pages une par une et de recopier les informations dans un tableau Excel. Gageons qu’il y consacrera souvent ses quinze jours de stage. Si vous mettez à profit un outil de Web scraping telle que la bibliothèque Beautiful Soup sous Python, cette tâche va pouvoir être automatisée et vous obtiendrez le résultat souhaité en quelques minutes !
Seulement voilà : les sites Web des grandes entreprises sont organisés de façon à favoriser une visite agréable de la part de l’internaute. Ils ne sont aucunement pensés dans une optique de faciliter l’analyse de leurs données par d’autres sociétés, habituellement concurrentes. Donc, autant le savoir, le Web scraping est une discipline complexe qui va impliquer une bonne dose de préparation avant l’usage effectif de Beautiful Soup…
Qu’est-ce que le Web scraping ?
Le Web scraping ou extraction de données du Web désigne les technologies qui aident :
- à extraire du contenu venant du Web de façon automatisée ;
- à assurer leur conversion dans des formats exploitables par des applications d’analyse : Excel, Google Sheets, Open Office Calc…
Pour effectuer du Web scraping, il faut donc en premier lieu savoir quel type de données l'on recherche au juste. À partir de là, il faudra repérer un site dans lequel figure l’information en question. De fait, de nombreux sites fourmillent d’informations en tous genres, notamment les sites marchands : objets d’une certaine catégorie, prix, notes données par les acheteurs… Seulement voilà : telles quelles, ces données sont inexploitables par un data analyst. Il faut donc les extraire en vue de les transformer en tableaux Excel et pouvoir alors les classer selon certains critères, obtenir des moyennes, produire des courbes…
Or, chaque site suit une approche individuelle. Il est parfois nécessaire d’entraîner un outil de façon qu’il apprenne à repérer certains types de données sur les pages Web explorées. Souvent aussi, cette exploration sera faite par soi-même. Tout cela n’est pas simple ? Certes, mais le jeu en vaut la chandelle.
Comment fonctionne Beautiful Soup ?
Si l’on souhaite se servir de Beautiful Soup pour du Web scraping, il importe de savoir qu’il s’agira généralement d’une tâche ardue. Car en réalité, il va falloir maîtriser quatre disciplines complémentaires.
Le HTML et le XML
Les pages Web telles que celle que vous consultez actuellement sont codées dans un langage appelé HTML (et aussi dans un autre langage fondé sur le même principe, XML). Il s’agit de ce que l’on appelle un langage de balisage : le texte ou les médias qui apparaissent à l’écran sont codés au moyen de balises. À titre d’exemple, les titres de pages sont indiqués entre deux balises : <H1> et </H1>.
Le code HTML : <H1>Tout sur les trous noirs</H1> permettrait ainsi d’indiquer un style titre de niveau 1 pour le texte « Tout sur les trous noirs ». Dans les principaux navigateurs tels que Chrome ou Firefox, il est possible de faire apparaître ce code HTML en appuyant sur les touches Ctrl Maj I.

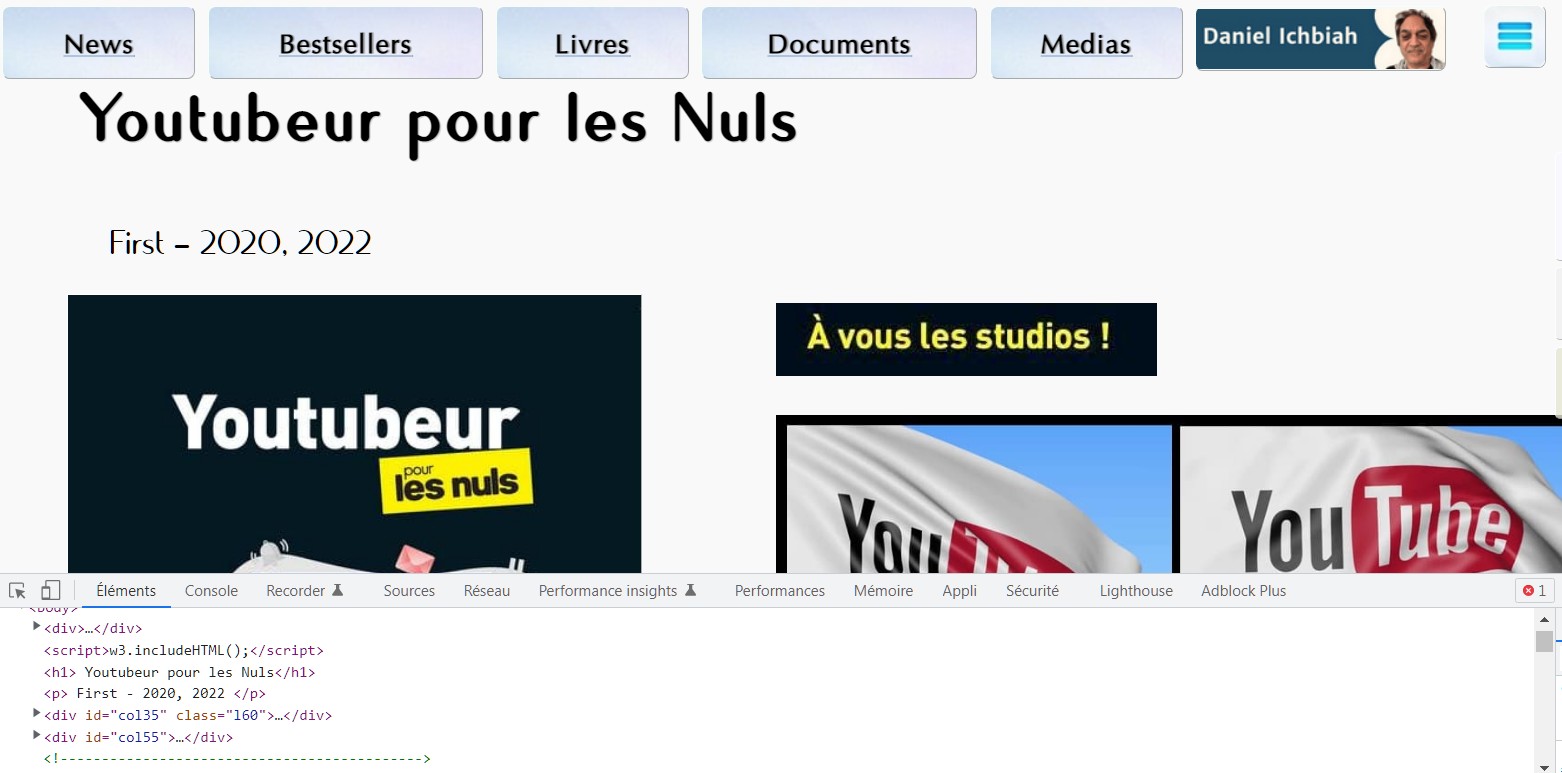
Si l’on souhaite maîtriser le Web scraping, il est donc essentiel d’avoir quelques notions de l’HTML, d’être familier avec ce codage car il faudra aller chercher les informations que l’on souhaite exploiter au sein d'un « charabia » a priori sibyllin. Le codage HTML peut être intimidant au premier abord, mais c’est essentiellement une question de pratique.
Imaginons que vous cherchiez à repérer des informations telles que des noms de produits par exemple, vous découvrirez en analysant un site marchand que ceux-ci ont pu être référencés par des mentions HTML comme :
- Class= « nom-produit » ;
- Class= « product_ide ».
Pour les prix, ce pourrait être :
- Class= « prix_ttc » ;
- Class= « current-price ».
En d’autres termes, celui qui a créé la page Web a établi son propre système de référence et il importe de savoir le décoder. En soi, une telle opération n’est pas excessivement complexe car, rappelons-le, vous pouvez pointer sur un élément d’une page Web et faire apparaître le code HTML correspondant. Il est toutefois nécessaire d’avoir acquis une certaine familiarité avec ce codage pour aller de l’avant.
Sachez-le toutefois : certains sites Web – environ 20 % – sont particulièrement difficiles à « scraper ». Ils ont été volontairement conçus ainsi. Cette difficulté pourrait décourager un data analyst de tenter son exploration.
Autre souci : certains sites Web modifient de temps à autre leur structure et donc leur codage HTML. Le programme que l’on aura donc pu écrire avec Beautiful Soup pourrait se révéler inexploitable à la faveur d’une mise à jour majeure.
Envoyer une requête au site Web
Avant de pouvoir procéder à l’analyse d’un site Web avec Beautiful Soup, il faut en premier lieu adresser une requête à ce site afin de pouvoir accéder à ses données. Une bibliothèque Python telle que Requests, ou une API (interface de programmation) comme REST, devra être mise à profit pour accéder au serveur concerné.
Il vaut mieux le savoir : certains sites, notamment ceux de fnac.com, Facebook ou LinkedIn sont fermés au Web scraping. Il est possible d’en avoir le cœur net en consultant le fichier robots.txt de ces sites Web. Celui qui s’aventurerait à outrepasser les protections mises en place et à extraire des informations de tels sites pourrait encourir des risques juridiques.
Sachez aussi que certains sites, qui sont a priori ouverts à une exploration, ferment l’accès dès lors que l’extraction de données est pratiquée trop souvent à leur goût depuis une même IP.
Organiser les données avec Beautiful Soup
Une fois l’accès au site obtenu, Beautiful Soup est en mesure de renvoyer des informations organisées, présentées de manière élégante. Avant l’intervention d’un outil tel que Beautiful Soup, ce que l’on récupère est une suite de texte extrêmement difficile à déchiffrer. Telle est donc l’action de cet outil : transformer cette « soupe » en quelque chose de présentable. Soit dit en passant, c’est de là que Beautiful Soup tire son nom. Cet outil inventé par le programmeur Leonard Richardson en 2004 est capable de transformer la « soupe » HTML en quelque chose de soigneusement présenté et donc plus aisé à analyser.


Envoyer les données extraites vers un tableau Excel
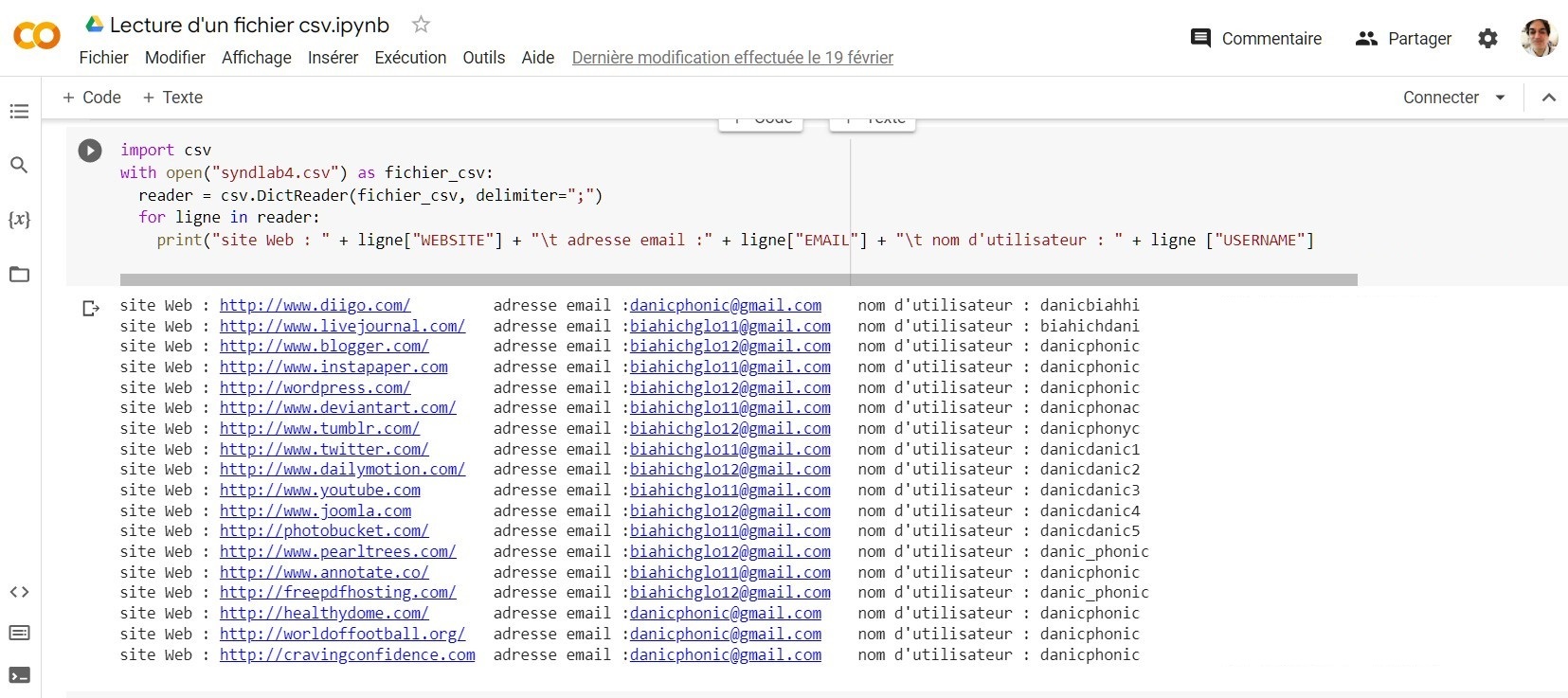
Dernier point : afin de pouvoir traiter les données ainsi extraites, il importe de pouvoir les exporter vers un tableau aisément lisible sous Excel. Le format couramment utilisé pour ce faire est le CSV, soit des suites d’informations séparées par un signe particulier, habituellement la virgule ou le point-virgule. La première ligne d’un tel tableau comporte habituellement les en-têtes de colonnes.
Voici, par exemple, l’allure d’un fichier CSV :
- Prénom, Nom, Média ;
- Sabrina, Bounali, Arte ;
- Fabien, Buchard, CNET ;
- Claudie, Gaminole, C News ;
- Geraldine, Guantana, D17 ;
- Maylis, Kessyie, France 2.
Depuis un outil comme Excel ou Google Sheets, ces informations vont apparaître sous une présentation claire et tabulée :
Prénom | Nom | Média |
Sabrina | Bounali | Arte |
Fabien | Buchard | CNET |
Claudie | Caminole | C News |
Géraldine | Guantana | D17 |
Maylis | Kessyie | France 2 |
Il est possible d'utiliser Beautiful Soup pour convertir des données d'un site Web en un fichier .CSV.

De quoi se compose une procédure de Web scraping avec Beautiful Soup ?
Récapitulons-nous. Une action de Web scraping comporte habituellement quatre étapes :
- Inspecter le site et son codage (en HTML) afin de repérer les éléments à extraire.
- Envoyer une requête au site – il peut arriver que celui-ci refuse qu’on le soumette à une analyse automatisée.
- Extraire les informations souhaitées de façon organisée avec Beautiful Soup.
- Exporter ces données sous la forme d’un tableau exploitable sous une application comme Excel.
Quels usages pour Beautiful Soup ?
Beautiful Soup est mis à profit dans diverses industries ayant à analyser des données issues du Web :
- surveillance de tendances sur des produits ;
- analyse des performances de la concurrence ;
- analyse de sentiment du public par rapport à un thème donné ;
- évolution d’un marché tel que celui de l’immobilier ;
- estimation de rendement (location, valeur d’un bien à la vente…) ;
- surveillance des prix ;
- investissement, etc.
Quels sont les avantages et inconvénients de Beautiful Soup ?
Les avantages de Beautiful Soup sont multiples :
- Beautiful Soup est apparu en 2004 et il a subi de nombreuses évolutions. C’est donc un outil « mûr », qui en est à sa quatrième version et couvre bien les besoins de l’extraction Web ;
- une fois que l’on s’est bien familiarisé avec ses commandes, la recherche de types de données au sein d’une page Web paraît accessible en quelques lignes de code ;
- en raison de son ancienneté, il dispose d’une vaste documentation ;
- une vaste communauté en ligne propose des solutions aux problèmes que l’on est en mesure de rencontrer lors de l’usage de Beautiful Soup.
Il reste que son usage suppose d’être familier avec d’autres concepts, notamment le codage HTML des pages Web, et que la préparation d’une procédure de Web scraping peut être fastidieuse.
Comment peut-on se former à Beautiful Soup ?
La capacité à extraire des informations d’un site afin qu’il soit possible de les analyser est précieuse. Et donc, la tentation sera forte de pouvoir rajouter Beautiful Soup sur son CV de Data Scientist. Pourtant, nous l’avons vu, une formation solide est nécessaire, puisqu’elle va au-delà de la simple maîtrise des commandes de Beautiful Soup. Il faut donc envisager une ou plusieurs semaines de formation.
Quelles sont les alternatives à Beautiful Soup ?
Octoparse
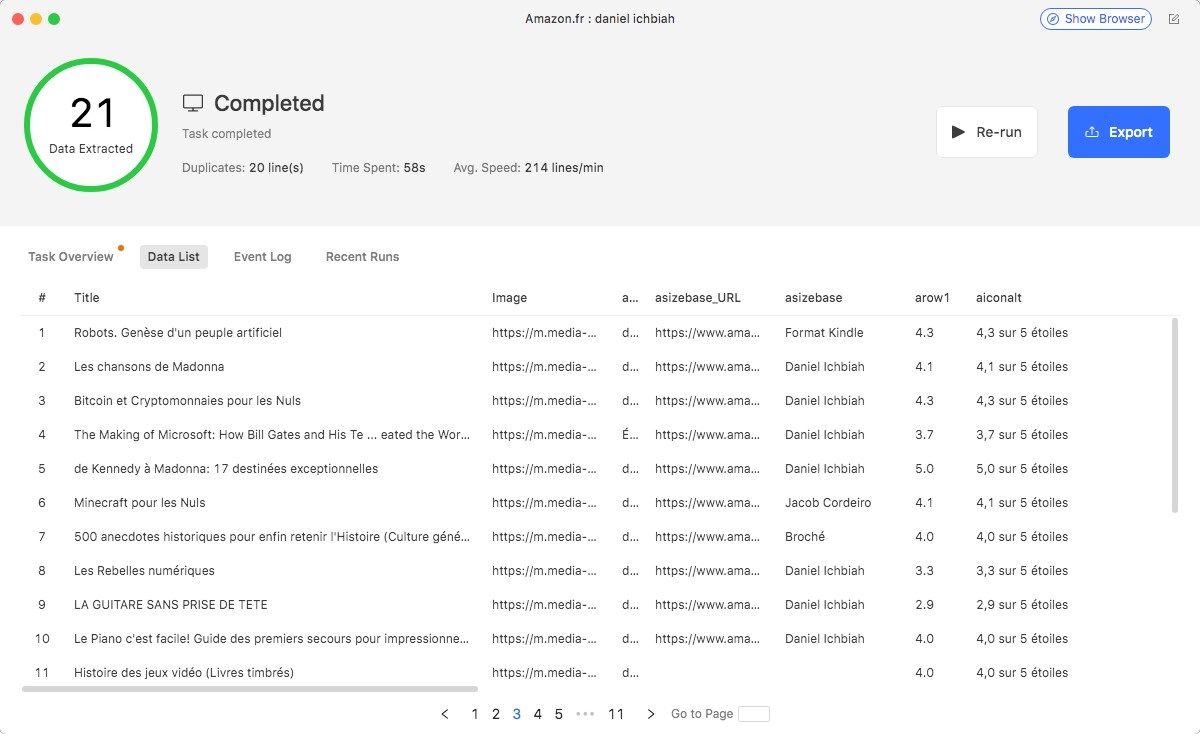
Un outil de Web scraping très aisé à prendre en main et dont l’avantage essentiel est qu’il ne nécessite aucune connaissance de la programmation. La facilité avec laquelle il peut analyser certains sites tels qu’Amazon est très appréciable. Qui plus est, la version payante de Octoparse inclut de nombreux « templates » (modèles prédéfinis) adaptés à des sites majeurs.

Web Scraper
Cette extension de Chrome revendique quelques 500 000 utilisateurs. Tout comme Octoparse, aucune programmation n’est nécessaire. Sa prise en main n’est pas aussi immédiate que celle d’Octoparse mais une fois que l’on a bien compris le principe, Web Scraper est d’un usage pratique puisque intégré au navigateur.
Scrapy
Scrapy est un outil open source qui fonctionne, tout comme Beautiful Soup, sous Python. Il permet lui aussi de programmer des analyses de sites Web. L’un de ses atouts est qu’il peut traiter des requêtes asynchrones, et donc accéder simultanément à plusieurs pages cibles et ce, fort rapidement. Il dispose d’une importante communauté d’usagers, ce qui peut être appréciable lorsqu’on cherche à accomplir une tâche peu habituelle. En revanche, sa prise en main est moins immédiate que celle de Beautiful Soup.







 sur la Lune ? C'est la vision proposée par Lonestar. © Jason Riley, Artificial Lens for Lonestar")








