

Python est le langage favori des programmeurs et la bibliothèque Pandas est devenue incontournable pour la Data Science ou l'exploitation intelligente de vastes volumes de données. Qu’est-ce qui fait la spécificité de Pandas ? Et comment expliquer une telle popularité ?
au sommaire
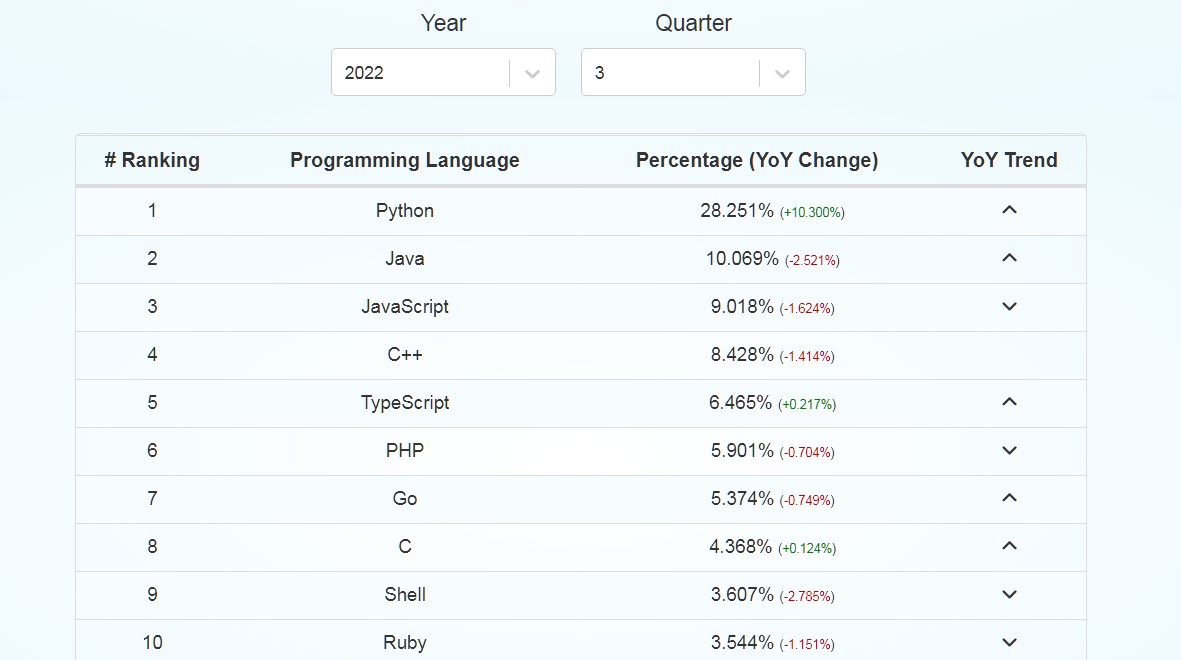
Apparu en février 1991, Python s’est progressivement imposé comme le langage de programmation vedette pour les applications Web. Une analyse effectuée sur le site de référence Github a montré qu’au 3e trimestre 2022, Python avait dépassé Java en matière de langage le plus utilisé, toutes applications confondues.
La raison est aisée à comprendre : la simplicité d’usage de sa syntaxe en a fait, peu à peu, l’outil de prédilection pour les développeurs. Il faut remonter au bon vieux Basic pour retrouver une telle simplicité. Certains se souviennent encore que, jadis, lorsqu’ils achetaient un micro-ordinateur Thomson TO7, un Amstrad, un Alice ou autre, celui-ci intégrait toujours un Basic. Par la force des choses, de nombreux programmeurs émérites ont fait leurs premiers pas en écrivant leur propre version de Tetris ou Space Invaders.
La grande force de Python est d’avoir offert une syntaxe aussi facile à manipuler que le Basic d’antan. Bien des développeurs le diront : on peut maîtriser les bases de Python et créer ses premiers programmes au bout de quelques heures. La différence s’arrête pourtant là : le rayon d’action et l’efficacité de Python sont sans commune mesure avec ce célèbre ancêtre qu’a été le Basic.

La bibliothèque Pandas, outil de prédilection des Data Scientists
Par la force des choses, de nombreuses bibliothèques de développement sont apparues afin de faciliter l’usage de Python dans des secteurs précis. La bibliothèque Python Pandas, pour sa part, est une bibliothèque en open source spécifiquement conçue pour analyser des données. En associant son utilisation à d'autres bibliothèques, il est ainsi possible de traiter et d'exploiter de très vastes volumes de données : c'est ce qu'on appelle aussi la Data Science. Il existe de nombreux outils adaptés à la Data Science, mais Panda s’est imposé par sa simplicité d’usage et sa flexibilité.
Sous Pandas, les informations sont présentées sous forme de « dataframes » soit des lignes et des colonnes, à la façon des tableaux créés avec Microsoft Excel, Google Sheet ou Pages. Certains ont même décrit Pandas comme l’équivalent d’Excel pour Python.
Avant l’apparition de bibliothèques telles que Pandas, de telles opérations sur des bases de données étaient habituellement effectuées de requêtes du langage SQL. Pandas simplifie fortement ces manipulations.
Comment a été créée Pandas ?


C’est un dénommé Wes McKinney qui est à l’origine de Pandas. En 2008, ce mathématicien, diplômé du prestigieux MIT (Massachusetts Institute of Technology), officiait chez AQR Capital Management, ce qui l’amenait à effectuer de nombreuses analyses financières. McKinney se montrait frustré par les outils logiciels mis à sa disposition. Lorsqu’il a découvert Python, il s’est entiché de ce langage mais a déploré le manque de fonctions prédéfinies d’analyse de données. Elles existaient en partie sous Excel et aussi dans le langage R — spécialisé dans les statistiques — mais McKinney n’était pas friand de telles solutions.
Wes McKinney s’est donc attelé donc à reproduire dans Python les fonctionnalités présentes dans R. Pour réaliser la bibliothèque Pandas, il s’est appuyé sur une bibliothèque existante : NumPy.
Panda a été rendu public en 2009. Un an plus tard, alors qu’il avait repris des études, McKinney a réalisé qu’il existait un réel potentiel autour de Pandas et s’est alors consacré à plein temps à bonifier cette bibliothèque. Puis, selon la logique du logiciel libre, d’autres programmeurs se sont greffés sur le projet et ont apporté leur propre contribution à cette bibliothèque.
Les atouts de Pandas ont fortement contribué à la popularité de Python. Partout dans le monde, des analystes de données ont découvert qu’ils pouvaient accomplir leur tâche bien plus aisément grâce à cet outil.
Comment fonctionne Pandas ?
Pandas fonctionne à partir de « tables » et donc de données disposées sous forme de lignes et de colonnes. Il peut opérer à partir de format de fichiers fort populaires, tels que Excel, ou encore le .CSV, mais aussi sur des bases de données de haut niveau comme celles gérées avec SQL. De fait, la polyvalence de Pandas est un de ses atouts majeurs. Une fois ces documents absorbés par Pandas et transformés en « data frames », il devient possible de leur appliquer des opérations statistiques ou encore des transformations via une plateforme interactive : le Jupyter notebook.
Associer des données de tableaux multiples
Par la force des choses, un Data Scientist ou un autre professionnel de la Data faisant appel à Pandas va se retrouver avec non pas un seul tableau, mais avec une multitude de tableaux dont les informations sont complémentaires. Or, l’une des forces de Pandas est de pouvoir opérer ce que l’on appelle une « jointure » sur plusieurs tableaux.
Un exemple simple : nous disposons d’une base de données incluant les noms de ville.
Nom | Ville | Hobby |
Martin | Paris 9e | Electronique |
Jonathan | Vielle Toulouse | Jardinage |
Mary | Bourg-la-Reine | Golf |
Albert | Metz | Lecture |
Dans une deuxième base de données, les villes sont associées au code postal :
Code postal | Ville |
Ambléon | 01300 |
Ambronay | 01500 |
Ambrutrix | 01500 |
Etc. |
|
À l’aide d’une jointure, il est aisé d’aller chercher le code postal dans cette deuxième table afin de l’associer à la ville.
Nom | Ville | Code postal | Hobby |
Martin | Paris 9e | 75009 | Electronique |
Jonathan | Vieille Toulouse | 31320 | Jardinage |
Mary | Bourg-la-Reine | 92340 | Golf |
Albert | Metz | 57000 | Lecture |
La capacité à agréger des sources d’informations très diverses et de pouvoir tirer la substantifique moelle de vastes réservoirs de données est une aubaine pour les professionnels de la data.
À quoi ça sert Pandas ?
La bibliothèque Pandas propose un grand nombre de fonctions relatives à des données tabulaires :
- exploration ;
- analyse statistique (moyennes, maximum, minimum, tendances, etc) ;
- visualisation sous forme graphique ;
- nettoyage des informations incohérentes ;
- etc.
L’ensemble fonctionne en mode interactif : on demande une statistique sur un vaste volume d’informations et le résultat est rapidement affiché.
Certains outils aident à transformer des sources d’informations multiples en une base exploitable ne comportant que des données jugées fiables, afin de pouvoir explorer ces données et en tirer des enseignements.
Un analyste pourrait ainsi importer une vaste base de données relatives à l’immobilier, afin de déterminer le prix moyen d’une maison par ville. Avec une opération appelée le « wrangling », il pourra opérer un filtrage intelligent, par exemple retirer les lignes comportant une maison à moins de 10.000 € sur la base qu’une telle information est très probablement erronée. Cette possibilité de « nettoyer » un tableau est essentielle pour le travail d’un analyste.
Qui s'en sert ?
Pandas est utilisé par plusieurs millions d’utilisateurs dans le monde, dans les corps de métiers les plus divers liées à la Data Science : commerce, assurance, économie, publicité, santé, immobilier, géographie, recherche fondamentale… Selon un sondage réalisé par le site Stack Overflow — dédié aux programmeurs —, la popularité de Pandas a doublé au cours des 4 dernières années, avec un taux d'utilisation qui est passé de 12,7 à 25%. La plupart des entreprises abritant des analystes de données dans leurs murs se servent de Pandas et cela inclut des sociétés telles que Google, Facebook ou JP Morgan.
Quels sont les avantages et les inconvénients ?
Tout comme Python, Panda est facile à mettre en œuvre, notamment dans la mesure où il est possible d’opérer à partir d’un simple fichier Excel ou CSV, comme sur de très vastes bases de données. Il reste que, avant d’acquérir une compétence dans Pandas, il faudra maîtriser quelques bases essentielles du langage Python.
Toutefois, la syntaxe de Pandas est très abordable : fondamentalement, grâce à cet outil, on peut écrire en 5 lignes de code fort simple, ce qui aurait normalement nécessité 50 lignes de code fort complexe.


Wes McKinney a rédigé le livre Analyse de données avec Python pour mieux expliquer comment fonctionne Pandas avec énormément de cas pratiques. © O’Reilly
Comment apprendre à se servir de Pandas ?
Une façon d’apprendre à maîtriser les arcanes de Pandas peut être de lire la prose de Wes McKinney, Analyse de données avec Python, livre dans lequel son créateur aborde un grand nombre de problèmes pratiques en la matière.
Pour ceux qui désirent maîtriser le sujet dans ses moindres détails, il existe une documentation officielle très complète — plus de 3.400 pages — accessible en ligne mais en langue anglaise. Nous recommandons également aux développeurs de télécharger la Cheat Sheet (feuille résumant les points essentiels).
Si vous souhaitez une approche plus progressive, des dizaines de tutoriels sont disponibles en ligne, notamment sur YouTube. Pour ceux qui souhaiteraient suivre une formation certifiante et professionnalisante à distance qui prépare à un métier de la Data, divers organismes professionnels proposent d’apprendre à utiliser Pandas pour les Data Analysts.
Quels sont les outils similaires ?
Parmi les outils similaires à Pandas, nous pouvons citer :
- Polar : un module de Python intégrant diverses fonctions de data science ;
- Ibis — un outil facilitant la manipulation de bases de données à partir de Python réalisé par Wes McKinney ;
- PySpark — une bibliothèque dédiée au traitement de données à grande échelle, avec une interface proche de Pandas ;
- Scikit Learn — une bibliothèque Python d’outils d’analyse prédictive dont le développement est piloté en France à l’Inria.





 modifie le monde du travail. © tippapatt, Adobe Stock")










