

Des chercheurs américains sont parvenus à reconstruire une scène en trois dimensions uniquement à partir de son reflet dans l’œil d’une personne. Pour cela, ils ont fait appel aux champs de de rayonnement neuronaux.
au sommaire
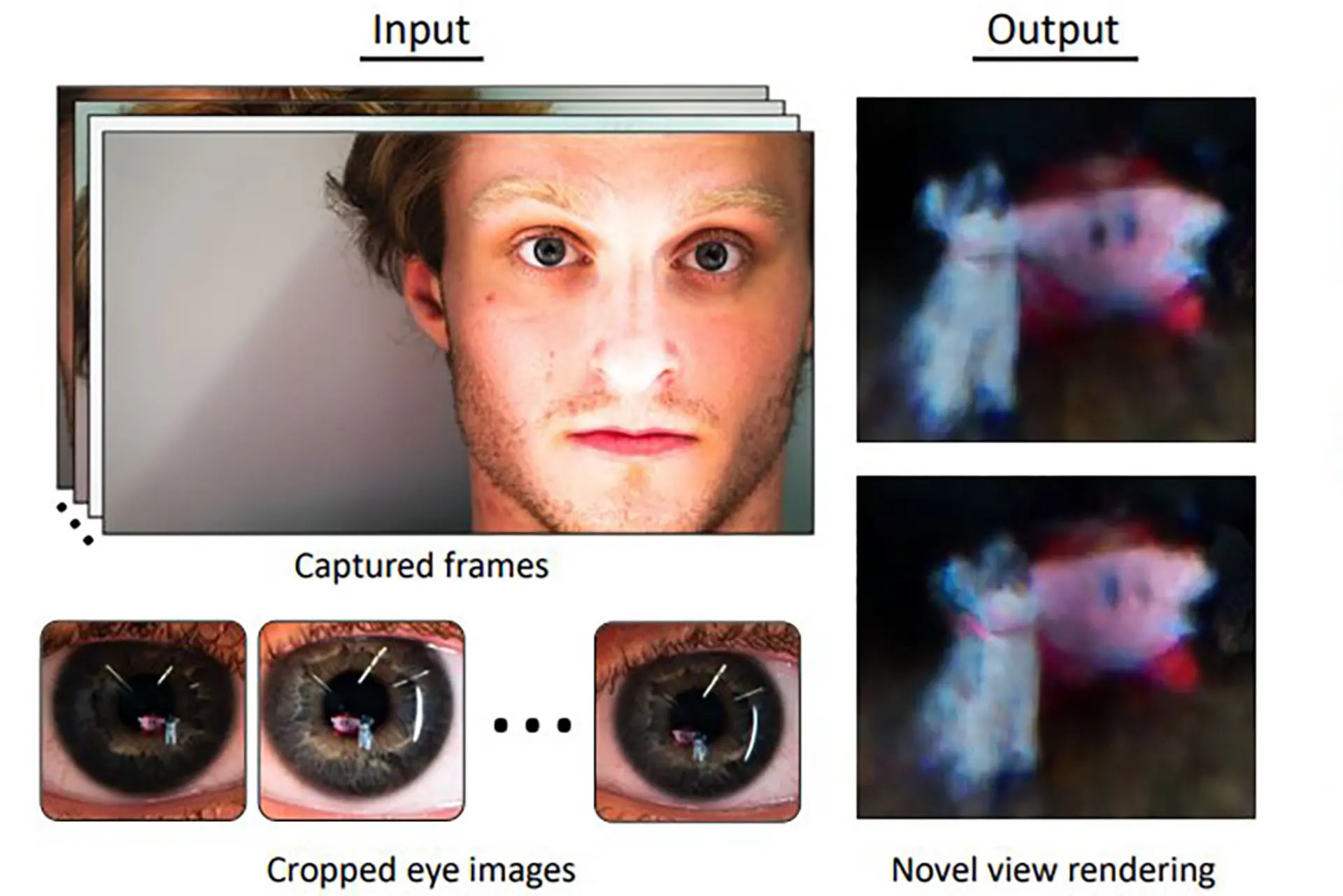
Les séries policières ont parfois recours à des techniques complètement irréalistes pour faire avancer l'histoire, comme par exemple zoomer sur l'œilœil de la victime dans une photo pour y voir le reflet de son tueur. Et pourtant, ce n'est plus de la science-fiction. Des chercheurs de l’université du Maryland aux États-Unis sont parvenus à reconstituer des scènes en trois dimensions à partir des reflets des yeux dans des vidéos.
Cette prouesse a été rendue possible grâce aux champs de rayonnement neuronaux ou NeRF (Neural Radiance Fields). Cette technologie est notamment utilisée par GoogleGoogle pour créer des vues en 3D détaillées de villes avec son Immersive View. Sauf que cette fois ce n'est pas la caméra qui se déplace, mais le sujet.

Quelques images en haute définition suffisent
Il suffit de quelques images haute définition de l'œil de quelqu'un qui se déplace pour reconstituer la scène. La forme de la cornée est suffisamment similaire chez les adultes en bonne santé pour permettre cette technique. Pour entraîner le champ de rayonnement neuronal, ils ont utilisé un rayon envoyé depuis la caméra. Ils ont également entraîné un algorithme pour retirer la texturetexture de l'irisiris.
Dans les tests réalisés dans des conditions optimales, avec des images haute définition et un bon éclairage, il est possible de reconnaître les peluches utilisées comme modèles par les scientifiques. Ils ont également testé leur technique sur des clips de Miley Cyrus et Lady Gaga, mais à cause de la qualité de l'image la forme obtenue est impossible à identifier. Les chercheurs ont publié plusieurs vidéos sur le site du projet et partageront bientôt le code source. Les chercheurs espèrent que cette technique pourra être utilisée pour découvrir d'autres sources de signaux visuels accidentels.









 ? © phonlamaiphoto, Adobe Stock")










. © Dall.E")


