

Il y a eu un avant et un après… Jusqu’en 2015 environ, gérer des applications de « deep learning » semblait une compétence réservée à quelques happy few. Et puis, Keras a changé la donne et mis ces outils à la portée de millions d’usagers…
au sommaire
Le langage Python est devenu populaire grâce à sa capacité à simplifier des activités ultra-complexes.
- Une bibliothèque Python telle que Scikit-learn est devenue incontournable pour le machine learning.
- Dès lors que l’on s’adonne à du calcul scientifique, l’usage de Numpy a de fortes chances d’apparaître comme la solution de choix.
- Si, en tant que data scientist, on opère dans l’analyse de vastes volumes de données, la tentation sera forte de recourir à la bibliothèque Pandas.
- Et pour la représentation graphique sous Python, la bibliothèque Matplotlib s’est imposée d’elle-même.
Il existe une branche de l’intelligence artificielle appelée le deep learning et qui requiert une expertise plus poussée encore que les disciplines évoquées précédemment. Et comme nous allons le voir, une fois de plus, Python est au rendez-vous…
Le « deep learning », c’est quoi au juste ?
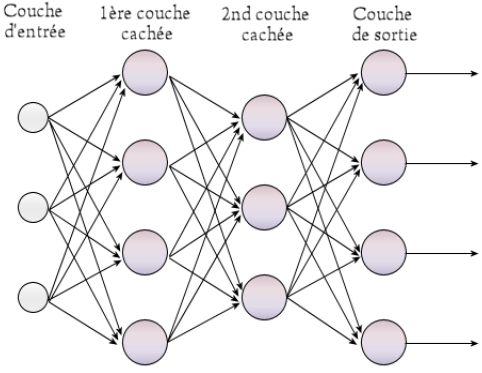
Le deep learning est une branche du machine learning, qui se concentre sur la résolution de problèmes complexes, en émulant l’activité du mental humain. Pour parvenir à ses fins, le deep learning utilise les réseaux de neurones artificiels.
Réseaux de neurones
Un réseau de neurones est une approche informatique potentiellement capable d’apprendre à réaliser n’importe quelle tâche.
C’est en 1943 que deux mathématiciens de l’université de l’Illinois ont inventé le concept des réseaux de neurones virtuels. De l’observation du fonctionnement des neurones de notre corps, ils ont émis l’idée que l’on devrait pouvoir créer des fonctions qui, à partir d’un signal en entrée, seraient à même de produire un signal avisé en sortie.
Il a toutefois fallu attendre 1957 pour que ce concept soit matérialisé une première fois avec le Perceptron de Frank Rosenblatt, un algorithme d’apprentissage répétitif qui opère sur le modèle des réseaux de neurones et qui est en mesure de déterminer des valeurs et tendances en fonction du résultat souhaité. Le problème, c’est que le Perceptron produisait des modèles linéaires. Or, dans notre vie, un grand nombre de phénomènes ne suivent pas un modèle linéaire.
En 1986, Goeffrey Hinton a inventé le Perceptron multi-couche qui prend en compte de vastes réseaux de neurones – et donc à plusieurs couches. Il a ainsi pu générer des modèles non linéaires à partir de phénomènes réels, et posé quatre étapes de résolution d’un problème.
- Forward propagation : les données circulent de la première à la dernière couche.
- Cost Function : un paramètre qui détermine l’efficacité d’un modèle de machine learning sur un ensemble de données.
- Backward propagation : les données circulent de la dernière couche jusqu’à la première.
- Gradient descent (descente de gradient) : un algorithme d’optimisation.
Le calcul redémarre en 1 et le cycle s’accomplit jusqu’à l’obtention d’un résultat satisfaisant.

En 1990, le Français Yann Le Cun a fait évoluer le concept en introduisant les « réseaux de neurones convolutifs », lesquels vont fortement faciliter le classement d’images. Le Cun a par la suite dirigé le laboratoire d’intelligence artificielle de Facebook/Meta et a reçu un prix Turing en 2019 pour ses travaux sur le deep learning.


En 2014, un autre concept majeur a été développé par les chercheurs Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau et Yoshua Bengio : les réseaux de neurones récurrents. Dans ce modèle, les informations calculées à un moment donné sont stockées en mémoire pour être réutilisées sur un prochain calcul.
Retenons que le deep learning fonctionne ainsi à partir de réseaux de neurones connectés les uns aux autres. « Deep » signifie profond et fait référence à la quantité de fonctions/neurones impliqués. Clairement, plus le réseau est profond et plus une machine est en mesure de résoudre des tâches complexes.
De la difficulté initiale de gérer le deep learning
Le souci avec le deep learning et les réseaux de neurones, c’est qu’il n’est réellement pas facile de les mettre en œuvre.
Parmi les API de « bas niveau » (voir les explications dans la section suivante) gérant le traitement de réseaux de neurone, figurent :
- TenserFlow de Google – ce produit a été mis sur le marché le 9 novembre 2015 et a été conçu pour pouvoir fonctionner sur de multiples microprocesseurs et GPU (processeurs graphiques) et aussi sur les OS de téléphones mobiles ;
- Theano – un produit développé par le MLA Groupe de l’université de Montréal au Québec et sorti en 2007. Il est programmé en Python mais génère un code C++ ;
- CNTK ou Cognitive Toolkit – un produit de Microsoft apparu en janvier 2016, incorporant du code C++ et du Python.
Seulement voilà, si l’on utilise un système de bas niveau, l’écriture du code est longue et fastidieuse. Keras a été développé avec pour objectif de faciliter une expérimentation rapide de tels outils. En d’autres termes, de pouvoir passer rapidement d’une idée à son implémentation…
Haut niveau et bas niveau
Keras est une interface de « haut niveau ». On parle de langage de « bas niveau » lorsque celui-ci manipule de façon plus ou moins directe un microprocesseur. Si l’on écrit un programme avec les instructions d’un langage de bas niveau, on obtient un traitement fort rapide. Un langage de « haut niveau » est bien plus facile à utiliser mais moins efficace.
Les origines de Keras
Keras a été originellement créé par le Français François Chollet, ingénieur logiciel chez Google. Il nous a raconté la genèse de Keras.


« J’ai démarré Keras avant d’avoir rejoint Google. Je l’ai lancé en mars 2015.
À cette époque, le deep learning était un monde fort différent. C’était une petite niche – il y avait probablement moins de 10 000 personnes dans le monde qui pratiquaient le deep learning. Tensorflow et Pytorch n’étaient pas encore là. Les outils de deep learning existants étaient destinés aux experts et généralement difficiles à utiliser. Tous ces outils sont morts aujourd’hui : Caffe, Lasagne, Pylearn2, Lua Torch, etc.
J’ai créé Keras parce que j’essayais d’appliquer des réseaux de neurones récurrents au traitement du langage naturel dans le cadre d’un projet personnel – j’avais démarré un an plus tôt un service de réponses à des questions appelé quickanswers.io : vous tapiez une question et obteniez une réponse instantanée. Il n’existait pas d’outil open source à cette époque, et en particulier pas d’implémentation de LSTM, l’algorithme de réseaux de neurones que je souhaitais utiliser. Keras a été la première implémentation du genre.
En d’autres termes, j’ai créé Keras parce que j’avais besoin de Keras.
Il faut voir aussi que jusqu’alors, tout ce qui avait trait au deep learning était particulièrement difficile à utiliser. J’ai donc fait de mon mieux pour rendre Keras facile et simple d’usage. J’ai notamment été inspiré par Scikit-learn, une bibliothèque Python réellement facile à prendre en main.
Six mois plus tard, j’ai rejoint Google. Je travaillais sur divers projets sans relations entre eux – notamment des recherches sur la vision par ordinateur pour Google Photos. En parallèle, je continuais d’améliorer Keras. Rapidement, le projet est devenu énorme.
En novembre 2015, Google a rendu public son propre système de deep learning, TensorFlow.
Dès la mi-2016, la plupart des grandes sociétés de tech avaient leur propre système de deep learning : MXNet, Chainer, Theano, TensorFlow, Keras, et un millier de bibliothèques plus réduites. Or, Keras représentait déjà environ 50 % du marché du deep learning – alors que j’étais seul à le mettre à jour lors de mon temps libre, avec un peu d’aide de la communauté Open Source.
À peu près à la même époque, j’obtenais énormément de feedback des utilisateurs de Keras et j’ai été pour le moins surpris : les gens utilisaient Keras pour résoudre des problèmes dont j’ignorais qu’il s’agissait de problèmes – comme l’automatisation d’une ferme d’élevage de poissons en Norvège. Cela m’a ouvert les yeux sur un fait : le deep learning est un outil incroyablement puissant. Nous n’allions pas en percevoir le potentiel intégral si nous attendions que les chercheurs de Google, Microsoft ou Amazon résolvent tous les problèmes que l’on pourrait résoudre avec. Pourquoi ? Parce que, pour commencer l’industrie de la tech, souvent, n’est pas consciente des problèmes que l’on pourrait résoudre avec !
Et donc pour réaliser le plein potentiel de l’IA, il nous fallait rendre ces technologies complètement accessibles, les placer dans les mains de quiconque a une idée et quelques compétences en codage. De cette façon, ceux qui sont familiers de certains problèmes peuvent commencer à les résoudre eux-mêmes. Un peu comme pour les sites Web : de nos jours, n’importe qui peut en créer un sans avoir à se reposer sur l’industrie de la tech.
Et c’est donc le futur que j’ai voulu bâtir : un futur où l’IA est un outil complètement accessible à qui ce soit.
En octobre 2016, le responsable de TensorFlow m’a contacté et m’a proposé de rejoindre leur équipe afin d’intégrer Keras dans TensorFlow. J’ai accepté. Puis, début 2018, les directeurs du projet TensorFlow ont décidé d’adopter Keras comme interface de haut niveau pour leur prochaine version majeure. Je n’ai eu aucune influence sur cette décision.
Depuis, Keras a été adopté par 2,5 millions de développeurs et c’est devenu la base de certains des systèmes d’IA les plus avancés du monde, notamment la Waymo, voiture auto-pilotée, ou encore le moteur de recommandation de Google. »
Keras, c’est quoi au juste ?
Résumons-nous :
- Keras est une interface de haut niveau pour la gestion du deep learning ;
- Keras est une bibliothèque Python open source qui facilite la mise en œuvre de réseaux neuronaux ;
- en tant qu’application de haut niveau, Keras exploite la puissance de bibliothèques de bas niveau telles que TensorFlow, CNTK, MXNet ou PlaidXML ;
- TensorFlow a adopté Keras comme son interface officielle.
Keras a ainsi représenté un tour de force, celui de rendre le deep learning accessible à un vaste nombre d’utilisateurs. Il offre notamment la possibilité de « prototyper » aisément des applications de deep learning. On estime que le nombre d’utilisateurs de Keras s’est multiplié par deux chaque année depuis son apparition. Parmi les géants du high-tech qui ont contribué au développement de Keras figurent non seulement Google mais aussi Microsoft, Amazon, et Nvidia.
Quels sont les usages typiques de Keras ?
Keras est couramment employé pour résoudre des questions de deep learning hautement complexes telles que :
- piloter une voiture en autonome ;
- effectuer des recommandations en fonction de ses propres goûts et de ceux d’une communauté ;
- entretenir une conversation intelligente comme le fait ChatGPT ;
- reconnaître et classer des images : chien, chat, etc. ;
- identifier des objets ;
- identifier des personnes sur une photographie ;
- jouer aux échecs...

Qui sont les grands utilisateurs de Keras ?
S’il fallait citer l’exemple le plus spectaculaire de l’usage de Keras, Waymo arriverait probablement en tête. Ce véhicule autonome – originellement connu comme la Google Car – est l’une des plus belles réalisations de l’intelligence artificielle. On dénombre plus de 25 000 de ces automobiles en usage et elles reposent sur des algorithmes de deep learning programmés avec Keras.


Parmi les autres grands usagers de Keras figurent Youtube, Netflix, Uber, Yelp, Square, Expedia (Microsoft), etc.
Quels en sont les avantages et les inconvénients ?
Les avantages de Keras sont multiples :
- les concepts manipulés par Keras sont relativement aisés à comprendre ;
- il est aisé de « prototyper » une application ;
- il est compatible avec la plupart des modèles de réseaux de neurones, notamment Tensorflow, CNTK, Theano, MXNet et PlaidXML ;
- une application peut s’exécuter sur un microprocesseur classique mais aussi sur un GPU (processeur de carte graphique). De plus, Keras gère les traitements en parallèle ;
- il est multiplateforme ;
- Keras est modulaire et donc flexible ;
- les applications que peut gérer Keras sont multiples, allant de la gestion d’un véhicule autonome à une app' sur smartphone ;
- la facilité de développement est telle que Keras a été mis à contribution lors de compétitions sur le deep learning.
Un autre atout de Keras est qu’il a bénéficié, lors son lancement, de l’apport de plus de 4 800 contributeurs, et cette communauté n’a cessé de croître : on estime qu’il y aurait 250 000 développeurs participant à l'amélioration continue de cette bibliothèque.
Cela étant dit, si le temps de réponse d’une application est un facteur essentiel, l’usage de Keras pourra être quelque peu pénalisant. Par définition, un langage de haut niveau va produire un code moins efficace qu’un langage de bas niveau. Si cette considération de vitesse était essentielle, il faudrait s’astreindre à développer l’application souhaitée directement à partir d’un langage de bas niveau. Si l’on utilise Keras avec Tensorflow, les temps de réponse seront relativement bons.
Comment peut-on apprendre à s'en servir aisément ?
Que faire si l’on souhaite devenir un Data Scientist confirmé grâce à Keras ? Démarrer l’apprentissage de Keras est relativement aisé, mais dès lors que l’on souhaite acquérir une compétence élevée sur le sujet, une formation approfondie apparaît inévitable.
À défaut, si vous pratiquez bien l’anglais, le site de référence de Keras propose des tutoriels accessibles à ceux qui ont une expérience ne serait-ce que minime du codage. Une fois les bases acquises, il sera avisé de consulter, tester et affiner les 10 modèles proposés sur la page Keras Applications et pré-entraînés sur la base de données d’images Imagnet. Pour perfectionner son apprentissage, on peut également tester les exemples Keras disponibles sur Github.

Quels sont les outils similaires à Keras ?
Si l’on souhaite approcher le deep learning via d’autres outils, il pourra être bon de s’intéresser à ceux-ci :
Posit
Posit (https://posit.co/) est le nouveau nom de Rstudio, une plateforme de Data Science bénéficiant d’une belle popularité. R, tout comme Python, est relativement accessible, bien adapté aux opérations statistiques et bénéficie d’une large communauté de développeurs.
Google Cloud AI
Comme il se doit, Google (https://ai.google/tools/) propose un accès à son outil TensorFlow mais aussi au MLKit, bien adapté au développement d’applications pour téléphones mobiles, et divers outils de deep learning, comme AI Sight qui est à même de détecter des objets dans des vidéos.
DataRobot
Il s’agit d’une plateforme cloud (https://www.datarobot.com/fr/) destinée, tout comme Keras à démocratiser l’accès à la Data Science et à faciliter le déploiement d’applications d’intelligence artificielle.
IBM Watson Studio
IBM propose de nombreux outils dans son offre Watson Studio spécialisée dans des outils d’intelligence artificielle (https://www.ibm.com/fr-fr/cloud/watson-studio/deep-learning) accessibles via un cloud, et cela inclut des outils spécifiquement adaptés au deep learning.







 espère améliorer la précision de ses prévisions. © IgorZh, Adobe Stock")


 ? © phonlamaiphoto, Adobe Stock")





