

Le machine learning a été une des révolutions majeures de l’Intelligence Artificielle. Et Scikit-Learn est l’outil de choix en la matière. Intégrée à Python, cette bibliothèque est une véritable caverne d’Ali Baba en matière de machine learning. Encore faut-il maîtriser les divers modèles accessibles, comprendre ce qu’ils recouvrent et savoir les employer à bon escient.
au sommaire
Les premiers programmes d’Intelligence Artificielle (IA) tentaient d’inculquer aux ordinateurs la façon de penser des humains. Ils opéraient en mode « que se passe-t-il si ? » et proposaient des actions à accomplir en fonction des situations rencontrées.
Pourtant, il a fallu se rendre à l’évidence : cette approche à base de règles prédéfinies selon la logique humaine n’était pas appropriée à la plupart des situations. Elle laissait échapper énormément d’opportunités. Des systèmes complexes que le fameux Open AI, qui est en mesure de produire des conversations intelligentes, opèrent à partir d’approches bien plus sophistiquées que celles de la programmation classique. Cette science porte un nom : le machine learning.
Qu’est ce que le machine learning ? Un sous-domaine de l’IA qui amène à programmer une machine afin que celle-ci puisse apprendre par elle-même. A partir de données expérimentales, le machine learning développe un modèle mathématique d’une fiabilité élevée – et mesurable. Une fois les règles ainsi définies, il devient possible de les appliquer à de nouvelles données, en vue de réaliser des prédictions ou de déduire des connaissances.
Point essentiel : si le machine learning amène un ordinateur à construire un modèle prédictif, a priori, il ne nécessite pas de programmation explicite préalable.
Scikit-Learn est une bibliothèque de l’écosystème Python spécialisée dans les travaux de machine learning…
Qu'est-ce que Scikit-Learn?
Autant le dire : pour celui qui souhaite pratiquer le machine learning, la découverte de SciKit-Learn a quelque chose d’un peu surréaliste. Quasiment tous les modèles et algorithmes de machine learning qui ont pu être développés à ce jour sont là, prêts à l’emploi !
Si vous êtes déjà familier avec le machine learning, pensez à un algorithme d’apprentissage supervisé que vous avez pu aborder. Eh bien, il y a de très fortes chances pour qu’il fasse partie de Scikit-Learn.
De ce fait, la bibliothèque pour le machine learning Scikit-Learn, également appelé « sklearn » est généralement considéré comme l’outil incontournable du machine learning. Intégré à l’ultra-populaire langage de programmation qu’est Python, Scikit-Learn apparaît comme la bibliothèque la plus complète et la plus robuste pour le machine learning disponible pour ce langage. Étant elle-même en grande partie écrite en Python, elle s’intègre naturellement dans cet environnement et peut donc profiter des atouts de bibliothèques telles que NumPy pour les calculs à haute performance ou encore Matplotlib pour la représentation visuelle des données.
Les outils de Scikit-Learn intègrent l’apprentissage automatique comme la modélisation statistique, et couvrent des fonctions telles que :
- La classification - l’identification et la catégorisation de données en fonction de modèles. Par exemple un outil de machine learning pourrait classer les messages reçus comme valides ou comme spam.
- La régression - la prédiction ou la projection de valeurs sur la base de la moyenne de données existantes / prévues. La régression peut être utilisée pour prédire les variations d’une valeur boursière.
- Le clustering - une technique regroupant des points de données par similarités – chaque groupe étant appelé un « cluster ». Ainsi, des données clients pourraient être regroupées par tranches de revenus.
- La réduction de dimensionalité – certains types d’informations d’une base de données sont volontairement ignorés afin de favoriser une analyse plus parlante.
- etc.
Comme d’autres projets Open Source, Scikit-Learn est un effort communautaire, potentiellement ouvert à la participation de quiconque. Le projet lui-même se trouve sur Github à cette adresse : https://github.com/scikit-learn/scikit-learn.
Comment Scikit Lean a-t-il été créé ?
C’est dans le cadre d’un « summer of code » de Google que Scikit-Learn a vu le jour en 2007, sous l’impulsion de l’ingénieur informatique français David Cournapeau, alors étudiant à l’université de Kyoto au Japon. Le « summer of code » est un programme organisé chaque année par Google en vue de promouvoir le développement du logiciel libre : des étudiants sont rémunérés pour réaliser un projet pendant l'été. En 2010, l’INRIA s’est fortement impliqué dans le projet avec la participation de Fabian Pedregosa, Gael Varoquaux, Alexandre Gramfort et Vincent Michel qui l’ont porté à un niveau supérieur, amenant la première version publique (v0.1 beta) a être déployée le 1er février 2010.


De nos jours, le projet – qui a bénéficié du soutien financier de Google, de la Python Software Foundation, de l’INRIA, de Tinyclues - recense quelques 35 contributeurs, dont Andreas Muller qui est l’origine d’une « cheat sheet » (aide mémoire) particulièrement utile pour bien comprendre le spectre couvert par les algorithmes de machine learning.
Comment fonctionne Scikit-learn ?
La force de Scikit Learn, c’est d’offrir une approche quasi identique pour toutes les situations de machine learning. Quelle que soit le modèle que l’on va mettre à contribution, trois mêmes « méthodes » nous sont proposées :
- fit() – pour entraîner le modèle sur un ensemble de données.
- score() – pour évaluer la fiabilité du modèle sur un autre ensemble de données.
- predict() – pour mettre le modèle en pratique sur un nouvel ensemble de données.
Quelle que soit la situation abordée, nous retrouvons ces trois instructions avec, certes, des variantes appropriées à un modèle donné.
Un exemple d’usage
Dans une vidéo d’introduction à Scikit Learn, le data scientist Guillaume Saint-Cirque aborde un problème pratique : aurait-il survécu au naufrage du Titanic ? Il a commencé par importer le dataset des données de 1 309 des passagers du Titanic. Il a ensuite filtré les colonnes afin de n’en conserver que quatre : survived (a survécu ou non), classe, sexe et âge. Puis, il a transformé les valeurs mâles / femelles en 0 et 1, afin de n’œuvrer que sur des données numériques. Nous avons donc à présent un dataset restreint appelé titanic().
A partir de là, il est nécessaire de choisir la fonction appropriée de Scikit Learn et ici, c’est KNeighbourgsClassifier qui a été sélectionné. Elle détermine une probabilité qu’une donnée fasse partie d’un groupe particulier.
La séquence Python pour charger cette fonction est la suivante :
from sklearn.neighbours import KNeighboursClassifier
model = KNeighboursClassifier
Pour pouvoir utiliser cette fonction, il est nécessaire de séparer la colonne y (survived) de x (les autres colonnes). En Python, une telle séquence est très simple :
y = titanic[‘survived’]
x = titanic.drop(‘survived’, axis=1)
Cette dernière instruction, drop sélectionne toutes les colonnes à l’exception de survived.
A présent, la fonction KNeighboursClassifier de Scikit Learn peut entrer en jeu :
model.fit(x,y)
model.score(x,y)
0,831932773102497
La fonction fit() a entraîné KNeighboursClassifier sur le dataset du Titanic. Puis la fonction score() a renvoyé un coefficient de fiabilité de ce modèle : 83 % environ. En d’autres termes, à partir de l'analyse des données existantes sur les passagers du Titanic, la prédiction apportée par KNeighboursClassifier comme quoi un passager a survécu ou non est de 83 %. Comme nous pouvons le voir au passage, l’usage de score() est facultatif et certains pourraient être tentés de s'en passer mais il apparaît important de déterminer quel degré de confiance on peut apporter à l’analyse qui a été effectuée d’un dataset. Si ce coefficient était trop faible, il faudrait alors s'acharner à rassembler davantage de données et ainsi obtenir un score de fiabilité honorable.
A partir de là, on peut utiliser KNeighboursClassifier à des fins de prédiction :
model.predict(x)
nous renvoie ainsi pour chaque passager quelle était la probabilité qu’il ait survécu ou non selon son âge, son sexe et sa classe de passager.
Guillaume Saint Cirque a alors appliqué ce modèle à sa propre situation imaginée : 26 ans, masculin, 3ème classe. Et la fonction de Scikit Learn a alors estimé qu’il n’aurait pas survécu, tout en sachant qu’elle n’est fiable qu’à 83%.
Etre familier avec le machine learning
Avec Scikit Learn, le data scientist bénéficie du caractère interactif de Python et donc, il obtient rapidement une réponse à ses requêtes.
Toutefois, avant de pouvoir utiliser Scikit-Learn, il faut impérativement que le data scientist soit familiarisé avec la terminologie propre aux projets de machine learning. Des concepts tels que :
- Précision : la probabilité de réussite d’un modèle.
- Caractéristique (en anglais : feature) : l’équivalent d’une variable.
- Représentation : comment configurer les données afin qu’elles puissent être évaluées. Parmi les représentations figurent les arbres de données, les réseaux neuronaux, etc.
- Evaluation : une façon d’estimer la validité d’une hypothèse.
- Etc.
Il sera par ailleurs avisé que le data scientist maîtrise l’interopérabilité avec d’autres bibliothèques telles que NumPy, Pandas et Matplotlib.
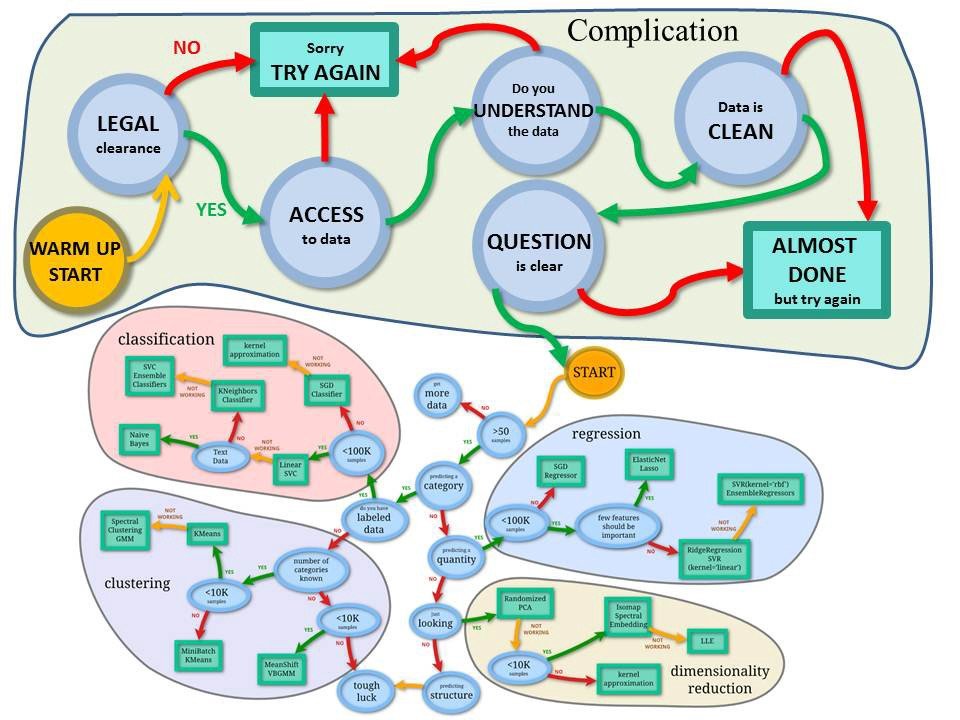
 créée par Andreas Mueller aide à comprendre le cheminement intellectuel du data scientist aux prises avec un problème de machine learning avec Scikit-Learn. © Andreas Muller")
À quoi ça sert ?
A partir du vaste volume de données manipulées dans les applications de Big Data, Scikit-Learn permet de construire des modèles prédictifs élaborés. Ses usages sont extrêmement diversifiés et couvrent des domaines tels que :
- les véhicules autonomes,
- la reconnaissance vocale,
- la prédiction du comportement des consommateurs,
- le diagnostic médical,
- l’identification d’activités suspectes,
- la prédiction de prix,
- la détection de fraudes,
- etc.
Qui s'en sert ?
Scikit-learn est mis à contribution par de très nombreuses entreprises, centres de recherches ou universités. C’est notamment le cas de Booking.com, de l’INRIA, de Spotify, d’Evernote, de JP Morgan, de AWeber, de BNP Paribas Cardif et bien d’autres.
Ainsi, chez Booking.com, ses algorithmes servent à la recommandation d’hôtels et de destinations ou encore à la détection de réservations frauduleuses. A l’INRIA, il soutient la recherche fondamentale de pointe dans des secteurs tels que la sécurité, l’analyse d’images médicales ou encore la vision assistée par ordinateur. Et sur Spotify, lorsque l’application recommande des chansons en fonction de ce que nous écoutons couramment, c’est encore Scikit-Learn qui est à l’œuvre. BNP Paribas Cardif (branche assurance de ce groupe) s’en sert pour classifier de façon automatique les données clients et ainsi améliorer ses services notamment l’accélération du traitement de certains sinistres.

Quels sont les avantages et les inconvénients de Scikit-Learn ?
Si Scikit-Learn est devenu un standard de facto des implémentations de machine learning, c’est en raison d’une conception réellement futée et d’une interface aisée – celle de la famille du langage Python. De fait, une fois que l’on a savamment maîtrisé le sujet du machine learning et son usage dans Scikit-Learn, il suffit généralement de quelques lignes de code pour définir un modèle prédictif et pouvoir le mettre en pratique. Un autre avantage, c’est que toute une communauté d’afficionados gravite autour de Scikit-Learn et apporte un soutien actif à ses utilisateurs. La simplicité d’usage de Python dans des interfaces comme Jupyter a également contribué à la popularité de cette bibliothèque.
En revanche, Scikit-Learn sert à bâtir des modèles prédictifs et devrait être limité à cet usage. Il n’est pas idéal pour la simple lecture, manipulation et synthèse d’information. Des librairies comme NumPy ou Pandas seront plus appropriées à une telle démarche. Retenons d’ailleurs que Scikit-Learn fonctionne fort bien en conjonction avec de telles bibliothèques.
Comment apprendre à s'en servir ?
Nous l’avons dit plus haut : Scikit Learn propose des outils de machine learning d’une grande simplicité, dès lors que l’on a pu se familiariser avec son approche. Cela ne veut pas dire pour autant qu’il ne faudra pas passer par un apprentissage conséquent.
En gros, le data scientist qui veut s’aventurer dans le royaume du machine learning doit maîtriser les divers modèles d’analyse existants afin de pouvoir déterminer quel sera le plus approprié dans une situation donnée. A partir de là, il pourra se lancer dans la manipulation de Scikit Learn à bon escient et en comprendre les usages optimaux. Il est possible qu’il doive tâtonner quelque peu, en particulier lors de ses débuts, afin de bien prévoir tous les paramètres à renseigner dans une instruction donnée. En effet, certains modèles de machine learning disposent d'options qui leurs sont propres.
Donc, autant le dire, quand bien même Scikit-Learn pourrait sembler relativement simple d’usage une fois qu’un data scientist connaît parfaitement ses divers modèles, apprendre à utiliser Scikit-Learn implique d’acquérir une compétence élevée dans le machine learning et ses applications. La maîtrise de chaque outil de Scikit-Learn au moyen de nombreux exercices pratiques paraît incontournable. Cela étant dit, cet apprentissage paraîtra relativement aisé au data scientist chevronné. Et comme il le découvrira, cette bibliothèque est fort bien documentée.

Quels sont les outils similaires ?
Il existe de nombreux outils de machine learning et d’autres solutions sont envisageables, notamment celles qui suivent.
- MLlib – cette bibliothèque fonctionne avec des commandes Python dans l’environnement logiciel Apache Spark. Elle est appropriée à des applications de machine learning relativement simples sur de grands ensembles de données.
- Keras / Tensorflow – cette bibliothèque Python est en mesure d’exploiter les processeurs de cartes graphiques, ce que Scikit-Learn ne sait pas accomplir nativement.
- Pytorch – une bibliothèque bien adaptée au « deep learning », une branche du machine learning qui s’appuie sur le modèle informatique des réseaux de neurones pour modèliser des données à un niveau d’abstraction élevé.
- Weka – des algorithmes de machine learning que l’on appeler depuis du code Java.





 espère améliorer la précision de ses prévisions. © IgorZh, Adobe Stock")




 ? © phonlamaiphoto, Adobe Stock")





, responsables de quelque 40 000 décès en France. © Ponchita, Adobe Stock")




")


