

Microsoft a développé VALL-E, une intelligence artificielle (IA) capable d'imiter une voix à partir d'un échantillon de trois secondes seulement. Certaines démonstrations sont très convaincantes. La firme a conscience du danger d'un tel outil placé entre les mains de personnes malveillantes.
au sommaire
Pour en apprendre plus sur cette actu, découvrez la chronique audio Vitamine Tech, où Emma Hollen vous parle en détail du fonctionnement de VALL-E. © Futura
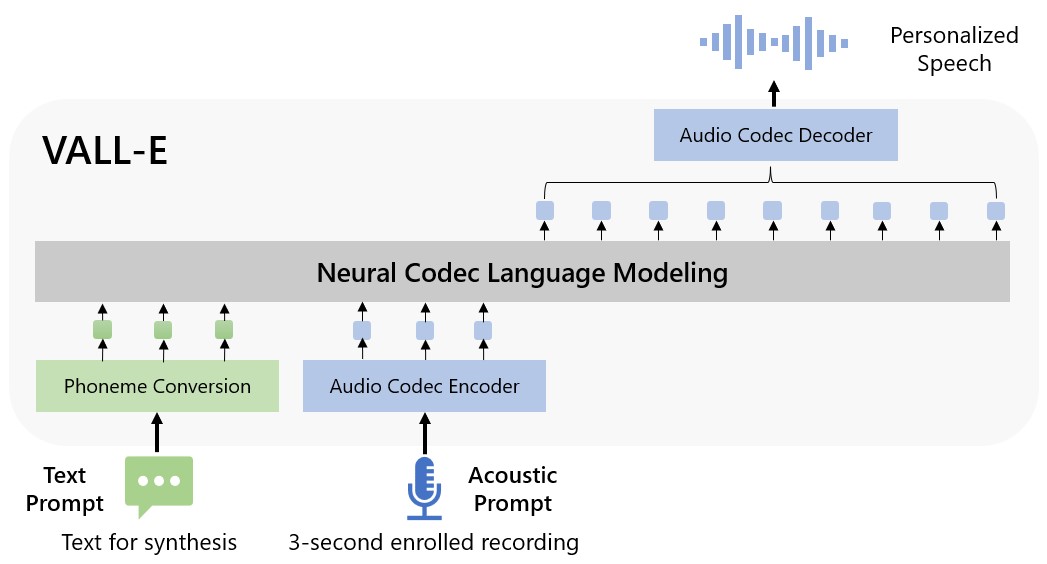
Après les « deep fake » en image ou en vidéo, va-t-on voir débarquer des « deep fake » sonores ? C'est possible puisque MicrosoftMicrosoft a dévoilé un nouveau modèle d'intelligence artificielle (IA) de synthèse vocale appelé VALL-E. Sa particularité ? Elle peut imiter et donc simuler la voix d'une personne avec un simple échantillon audio de trois secondes. Une fois qu'elle a appris une voix spécifique, cette IA peut synthétiser le son de cette personne, tout en préservant son timbre et les émotions.
Chez Microsoft, on pense que VALL-E pourrait être utilisé pour des applicationsapplications de synthèse vocale, mais aussi, et c'est évidemment plus inquiétant, pour l'édition de la parole dans un enregistrement. Il serait possible d'éditer et modifier le son à partir d'une transcriptiontranscription textuelle d'un discours. Imaginez une allocution d'un homme ou d'une femme politique modifiée par cette intelligence artificielle...

Le « machine learning » en action
Pour la firme, VALL-E est ce qu'on appelle un « modèle de langage de codec neuronal », et il s'appuie sur une technologie de compression audio appelée EnCodec, dévoilée par Meta (FacebookFacebook) en octobre dernier. Contrairement à d'autres méthodes de synthèse vocale qui synthétisent généralement la parole en manipulant des formes d'onde, VALL-E génère des codes de codec audio à partir d'échantillons textuels et acoustiques. Il analyse essentiellement le son d'une personne, décompose ces informations en tokens (jetonsjetons) grâce à EnCodec, et il utilise le « machine learningmachine learning » pour faire correspondre l'échantillon de trois secondes avec ce qu'il a appris.
Pour cela, Microsoft s'est appuyé sur la bibliothèque sonore LibriLight. Elle contient 60 000 heures de discours en anglais de plus de 7 000 locuteurs, principalement tirés des livres audio du domaine public LibriVox. Pour que VALL-E génère un résultat pertinent, la voix dans l'échantillon de trois secondes doit correspondre étroitement à une voix dans les données d'apprentissage.
I must do something about it.
Un exemple. © VALL-E
Microsoft a conscience du danger
Pour vous convaincre, Microsoft fournit des dizaines d'exemples audio du modèle d'IA en action. Certains sont effrayants de similitude, mais d'autres sont clairement synthétiques et l'oreille humaine parvient à distinguer que c'est une intelligence artificielle. Ce qui impressionne, c'est qu'en plus de préserver le timbre et l'émotion de la personne qui parle, VALL-E est capable de reproduire l'environnement et les conditions de l'enregistrement. Microsoft prend l'exemple d'un appel téléphonique avec les propriétés acoustiques et fréquentielles propres à ce type de conversation.
Interrogé sur les dangers d'une telle intelligence artificielle, Microsoft confirme que le code sourcecode source n'est pas disponible, et la firme a conscience que « cela peut entraîner des risques potentiels d'utilisation abusive du modèle, tels que l'usurpation d'identification vocale ou l'usurpation d'identité d'un locuteur spécifique. Pour atténuer ces risques, il est possible de construire un modèle de détection pour discriminer si un clip audio a été synthétisé par VALL-E. Nous mettrons également en pratique les principes de Microsoft AI lors du développement ultérieur des modèles ».






 ? © phonlamaiphoto, Adobe Stock")









, responsables de quelque 40 000 décès en France. © Ponchita, Adobe Stock")




")


