

L'intelligence artificielle de Google ne se contente plus de traduire en temps réel dans une autre langue puisqu'elle sera aussi capable de le faire en conservant votre accent et votre voix. C'est la prouesse de Translatotron sur lequel des ingénieurs de Google travaillent.
au sommaire
Avec l'essor de la reconnaissance vocale ces dernières années, qui a permis notamment le développement des assistants vocaux tels que SiriSiri ou AlexaAlexa, de nouveaux outils de traduction ont émergé. Il existe désormais divers outils qui tentent de concurrencer l'interprète humain, mais leur fonctionnement reste relativement robotique et de nombreuses nuances de la langue sont perdues au passage.
GoogleGoogle travaille sur un traducteur vocal d'un nouveau genre. Les traducteurs classiques se basent sur trois modules séparés. Un premier module reconnaît les paroles et les transcrit sous forme de texte. Un deuxième module traduit le texte d'une langue vers une autre. Le troisième module est la synthèse vocale, qui lit le texte traduit à voix haute. Les avancées autour de l’intelligence artificielle, notamment dans les techniques de deep learning, ont permis des progrès considérables pour chacun des trois modules, mais le résultat combiné reste limité.
Un système qui fonctionne sans passer par le texte
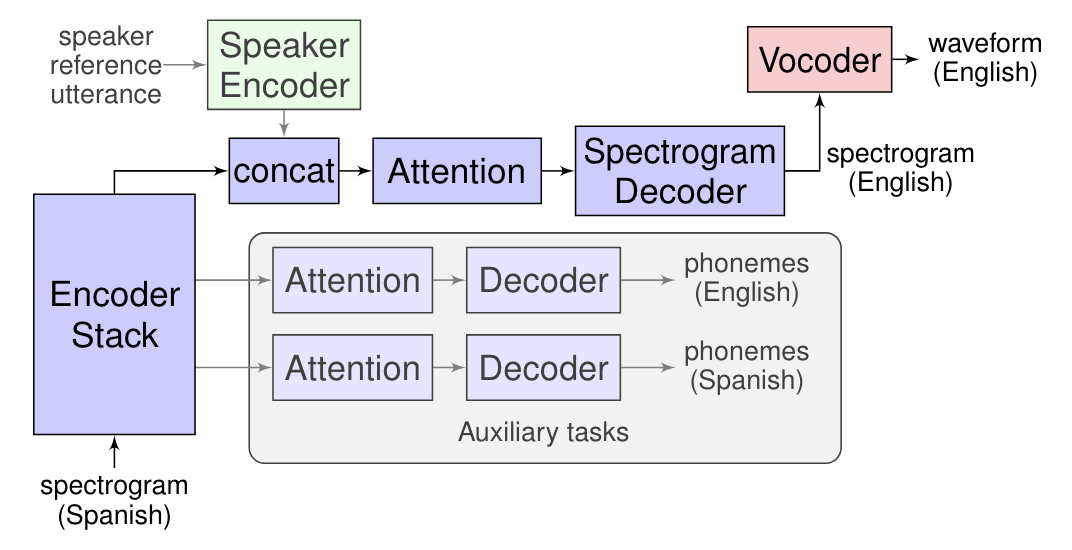
Sur le blog d’intelligence artificielle de Google, des ingénieurs de la firme ont présenté leurs recherches sur un nouveau système de traduction, qui est décrit comme étant la traduction parole à parole directe avec un modèle séquence à séquence. Ce système, baptisé Translatotron, effectue la traduction vocale directement, sans passer par un module texte. Il présente l'avantage d'éviter le cumul d'erreurs entre la reconnaissance vocale et la traduction écrite, d'augmenter la vitessevitesse de traduction, une meilleure gestion des mots qui n'ont pas besoin d'être traduits (comme les noms) et permet de surcroît de garder un certain nombre de caractéristiques de la voix du locuteur après la traduction.
Les premiers modèles séquence à séquence ont été créés en 2016, et dès 2017 l'équipe de chez Google avait démontré que ces nouveaux modèles avaient le potentiel d'atteindre de meilleures performances que les systèmes traditionnels, appelés modèles en cascade.

Un modèle encore en développement
Translatotron fonctionne en utilisant des spectrogrammes source, et génère des spectrogrammes du contenu traduit dans la langue cible. À ceci sont ajoutés deux composants qui ont été entraînés séparément. Le premier est un vocoder neuronal qui convertit les spectrogrammes générés en ondes temporelles. Le second est un encodeurencodeur vocal qui permet de garder les caractéristiques de la voix du locuteur lors de la synthèse vocale.
Google a utilisé l'algorithme BLEU pour vérifier la qualité de la traduction. L'algorithme note la qualité de la traduction sous forme de texte, l'équipe a donc dû faire appel à un système de reconnaissance vocale. Les résultats ont montré que pour l'heure Translatotron atteint un niveau de qualité un peu en dessous des systèmes en cascade, mais ils ont pu valider la faisabilité de leur approche. Les chercheurs ont fourni un certain nombre de clips audio afin de montrer les résultats d'une traduction de l'espagnol vers l'anglais, avec l'original, la version traduite par un humain, la version obtenue avec un système en cascade, et enfin le résultat du système Translatotron.
Ce qu’il faut
retenir
- La traduction est aujourd'hui effectuée par des voix robotiques.
- Google cherche à conserver l'accent et la voix de celui ou celle qui parle.
- Une traduction qui s'effectue en trois étapes où l'intelligence artificielle joue un rôle essentiel.





 ? © phonlamaiphoto, Adobe Stock")









 sur le site de la Faculté des ressources aquatiques (Su Ürünleri Fakültesi). Google Translate, intégré à la barre d'outils, a traduit les textes de la page (mais pas les titres, qui sont en fait des images). (Capture d'écran.)")
, responsables de quelque 40 000 décès en France. © Ponchita, Adobe Stock")




")


