
au sommaire
, un doctorant du MIT, Mieszko Lis, a présenté la puce Execution Migration Machine (EM2). Ses 110 cœurs et son système complexe de prédiction logent sur un circuit de 1 cm2. © MIT")
, un doctorant du MIT, Mieszko Lis, a présenté la puce Execution Migration Machine (EM2). Ses 110 cœurs et son système complexe de prédiction logent sur un circuit de 1 cm2. © MIT")
Lors d'une présentation à la conférence Hot Chips à l’université de Stanford en Californie (États-Unis), un doctorant du MIT, Mieszko Lis, a présenté la puce Execution Migration Machine (EM2). Ses 110 cœurs et son système complexe de prédiction logent sur un circuit de 1 cm2. © MIT
Décupler le nombre de cœurs d'une puce pour réduire la consommation électrique et améliorer les performances, voici la combinaison à laquelle est parvenue une équipe de chercheurs du MIT (Massachusetts Institute of Technology)). Le prototype mis au point par les scientifiques porteporte le nom de Execution Migration Machine (EM2) et rassemble 110 cœurs sur une seule plateforme. Le principe de multiplication des cœurs (core) ne date pas d'hier et désormais tous les ordinateurs sont dotés de processeurs multicœurs, ce qui est également le cas pour les smartphones et les tablettes. Dès 2006, Intel a lancé un programme de recherches menant à déployer des dizaines de cœurs sur une seule puce. L'idée principale restait de réduire la consommation électrique des serveurs et des datacenters. Ce principe permet aux cœurs trop sollicités et qui pourraient surchauffer de transmettre leurs données aux cœurs inactifs. Au final, la puce gagne en temps d'exécution pour une consommation réduite.
Aujourd'hui, le maximum de cœurs employés culmine à 16 unités sur une puce de serveur. il existe bien des modèles, comme celui du fabricant français Kalray et son MPPA 256. Cette puce intègre 256 cœurs gravés en 28 nanomètresnanomètres et cadencés à 400 MHz. Elle serait quatre fois plus performante qu'un processeur quadricœur IntelIntel, pour une consommation divisée par dix. À la différence de cette puce, le prototype du MIT est gravé en 45 nanomètres et repose sur une architecture en maillage dans un design carré prévu pour traiter des gros volumesvolumes de données et accélérer au maximum leur trafic.
. Les bonnes connexions sont ainsi plus rapidement établies. © MIT")
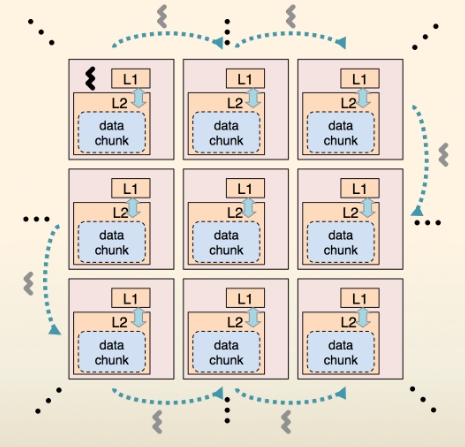
Pour réduire la durée de transit des données au sein de la puce entre les unités, ou cœurs, et diminuer la consommation électrique, l'équipe du MIT utilise un algorithme qui prévoit, autant que faire se peut, les futurs mouvements de données (data chunk, paquet de données). Les bonnes connexions sont ainsi plus rapidement établies. © MIT
Optimiser le transfert des données
Outre cet assemblage de cœurs, l'optimisation de la puce repose sur la méthode employée pour accélérer les transferts de données. Aux classiques niveaux de mémoire cache habituellement utilisés pour faire transiter les données entre les cœurs est substituée une mémoire partagée par l'ensemble des processeurs. Il y a beaucoup moins de canaux pour acheminer les données, qui circulent donc plus rapidement.
Et ce n'est pas tout. En plus de ce système, le laboratoire a mis au point un système de prédiction des mouvementsmouvements des données (threads). Il est donc capable de réduire considérablement le nombre de threads, ce qui apporte moins de consommation et plus de performances. Ainsi, selon les tests des scientifiques, à consommation égale, le trafic aurait été diminué de 14 fois pour des performances 25 % au-delà d'autres modèles de processeurs équivalents.
Si le principe de fonctionnement est séduisant, il faut savoir que les chiffres annoncés par le doctorant Mieszko Lis lors d'une présentation à la conférence Hot Chips en Californie de l'université de Stanford (États-Unis), qui s'est tenue du 25 au 27 août, n'indiquent pas quels modèles de processeurs ont été employés en référence. En outre, pour atteindre ce niveau de performances, le code employé dans les applicationsapplications doit être adapté afin de pouvoir être exploité correctement.

par Sylvain Biget, Futura
le 3 septembre 2013














. Crédit : Intel.")
, responsables de quelque 40 000 décès en France. © Ponchita, Adobe Stock")




")


