

Le Web est un réservoir titanesque d'informations, constamment mis à jour. Peut-on extraire de ce vaste creuset des données utiles pour son activité ? C'est ce que propose le Web scraping.
au sommaire
Quelle que soit l'activité que l'on pratique, la possession de certaines informations est en mesure de changer le cours des choses. Nous en avons un exemple dans le film Tout le monde dit "I love you". La patiente interprétée par Julia Robert se livre à des confidences et celles-ci sont espionnées par des gamines qui ont percé un trou dans un mur. Elles en font profiter Joe, le personnage joué par Woody Allen qui sert ainsi à la belle ce qu'elle veut entendre et peut ainsi la séduire.
Disposer d'informations cruciales est si précieux qu'une part majeure de l'activité de renseignement repose sur cette nécessité — une autre partie consistant à diffuser de fausses informations en espérant que celles-ci seront exploitées par d'autres gouvernements qui y accordent foi. Mais il n'est pas nécessaire d'agir sur une telle échelle pour ressentir la nécessité de détenir quelques tuyaux de nature cruciale. Ainsi, dans un jeu vidéo, être informé du point faible d'un monstre que l'on doit affronter peut faire la différence entre la victoire ou le game over.
En réalité, le Web est un méga-réservoir de données et qui plus est, en mutation permanente. Or, le propre de celles-ci est qu'elles échappent souvent à l'analyse rationnelle. Certains sites tels que Google Trends nous indiquent par exemple les tendances du moment. Ainsi, lors de la journée où ont été écrites ces lignes, alors que le sujet de jour aurait semblé être le vote d'une motion de censure à l'Assemblée, fort curieusement, c'est le mot « printemps » qui cristallisait le plus la curiosité des internautes.

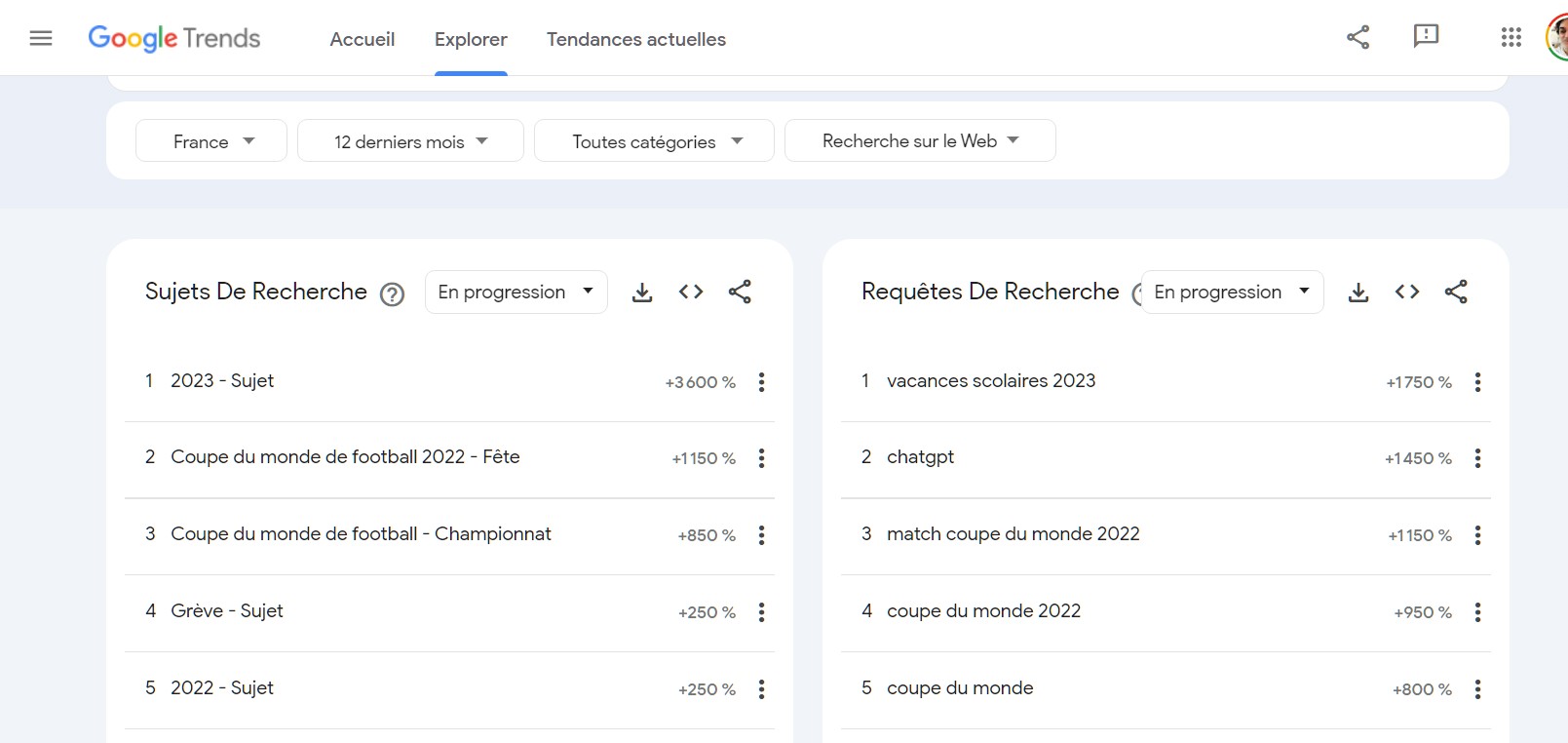
Par nature, le Web est ainsi le reflet d'une activité multiforme, un immense ballet qui met à contribution des millions de protagonistes. Savoir lire les tendances cachées en arrière plan de ce tourbillon peut donc s'avérer inestimable.
Or, c'est ce que permet une technologie : le Web scraping ou extraction de contenus du Web.
Voir aussi : Les meilleurs VPN du moment
Le Web scraping, c'est quoi au juste ?
Le terme Web Scraping englobe diverses technologies vouées à :
- l'extraction automatisée d'informations structurées depuis un site Web ;
- leur mise en forme sous un format aisément exploitable, tel celui d'Excel.
Pour mieux comprendre ce que recouvre cette activité, imaginons qu'elle soit effectuée « à la main ».
Vous chargez un employé ou un stagiaire d'explorer des sites de vente en ligne tel que celui de la Fnac, Amazon, CDiscount, Leboncoin ou autre afin de relever, pour tous les casques audio, leur prix, le nombre d'étoiles attribuées par les utilisateurs, leur classement dans les ventes… Objectif : recopier ces informations dans un tableau Excel de milliers de lignes. Un tableau qu'il sera possible d'analyser avec les outils statistiques appropriés ou dont on pourra classer les colonnes à son gré.
En temps normal, cette tâche devrait s'étaler sur plusieurs jours. En revanche, si l'employé chargé de cette mission est en mesure de s'appuyer sur un web scraper, alors la tâche pourra être accomplie en un temps bien plus court, et elle pourra être relancée à volonté, par exemple, chaque lundi. À chaque fois, l'outil va parcourir des dizaines de milliers de pages et rapatrier sa moisson en automatique.
N'allons pas croire pour autant que la tâche sera forcément aisée.
Comment fonctionne un Web scraper ?
L'utilisateur d'un Web scraper doit en premier lieu spécifier l'adresse du site ou des pages qu'il désire explorer. Il est nécessaire ensuite d'indiquer très précisément les rubriques qui doivent faire l'objet d'une analyse :
- nom d'un article ;
- catégorie ;
- prix ;
- notations…
Le Web scraper va alors explorer les pages indiquées et produire le plus souvent un fichier .CSV que l'on peut ouvrir sous Excel, Google Sheets.
Quels sont les usages typiques du Web Scraping ?
Voici une liste non exhaustive d'activités pouvant bénéficier du Web scraping.
-
Comparaison de prix
Si vous pratiquez la commercialisation d'un type d'article, vous devriez avoir à cœur de comparer les tarifs proposés par les grands sites de e-commerce, et ce, idéalement au jour le jour.
-
Statistiques et tendances
Pour de nombreuses entreprises ou cadres, il est précieux de savoir quelle sont les tendances de recherche des internautes dans un domaine, ou l'évolution de la demande dans un secteur particulier.
-
Affiliation
Certains sites se targuent de repérer de bons plans et de diriger leurs visiteurs vers ceux-ci. On parle alors d'affiliation car le site de conseil est rémunéré en fonction du trafic qu’il amène au site destinataire. Par la force des choses, le web scraping aide à repérer les bons plans en question. On trouve notamment cette activité dans l'immobilier.
-
Analyse de sentiments
Les médias, les hommes politiques mais aussi les entreprises sont curieuses de connaître le sentiment du public par rapport à un thème. Le Web scraping peut donc aider à décoder quelle est l'humeur générale sur un sujet à un moment précis.

Les types de Web scraping
-
Extensions du navigateur Web
Assez souvent, le Web scraping est opéré depuis un navigateur Web comme Chrome ou Firefox. Avantage : l'utilisateur peut ordonner la capture d'informations « à la volée ». S'il visite un site qu'il juge digne d'intérêt, il peut alors activer une extension de Web scraping et la paramétrer en inspectant la présentation des informations.
-
Application personnalisée
Dans certains cas de figure, le plus adéquat sera de réaliser un outil personnalisé de Web scraping, en utilisant un langage tel que Python. Le revers est qu'il est nécessaire d'avoir au préalable une bonne maîtrise de la programmation.
-
Logiciel de scraping
De nombreux logiciels de Web scraping sont sur le marché et ils ont des possibilités de paramétrage habituellement plus étendues que les extensions de navigateur. Il est généralement nécessaire de dédier une machine de haute capacité à cette activité potentiellement vorace en temps machine sur plusieurs heures d'affilée. De fait, il arrive qu'un outil de Web scraping soit amené à analyser des millions de pages.
-
Web scraping sur le Cloud
Certains fournisseurs de service de Web scraping proposent que l'on puisse opérer depuis leur propre serveur et donc, sans pénaliser l'informatique locale.
Les obstacles au Web scraping
Une fois que l'on a bien défini la mission à accomplir par un web scraper, celui-ci va normalement accomplir sa tâche avec vélocité. Toutefois, l'étape préparatoire risque d'être longue. Les raisons en sont multiples.
-
Des formats multiples
Les sites Web sont conçus de façon à être agréables à consulter par leurs visiteurs. Ce facteur de convivialité est primordial. Les créateurs de sites Web n'ont cure des programmes d'exploration et d'analyse tels que les web scrapers. À vrai dire, s'ils peuvent leur compliquer la tâche, ils n'hésiteront pas à le faire, car pourquoi faire profiter ses concurrents du trésor que constituent des données clients ?
Ainsi donc, une application de web scraping doit être amenée à identifier les sections précises d'une page Web qui intéressent l'analyste. Pour ce faire, il est parfois nécessaire de s'immiscer dans le code interne d'une page Web et d'avoir une maîtrise ne serait-ce que minimale des langages qui ont permis sa création : HTML, CSS, javascript, XML…
-
Les captchas et antibots
Certains sites Web se servent de « captchas » afin de vérifier qu'ils sont visités par des humains et non par des robots. Il existe divers systèmes de contournement automatique des captchas, et leur efficacité est plus ou moins grande. Il arrive aussi que certains sites analysent le comportement de certains visiteurs et identifient un « bot » tel que le Web scraper auquel cas, ils lui bloquent alors l'accès. Certains services parviennent à contourner de telles limitations par exemple en multipliant les IP depuis lesquelles le Web scraper donne l'impression de se connecter et en espaçant les requêtes d'une manière qui apparaît naturelle.
-
Aspects légaux
Il arrive aussi que certains sites protègent leurs informations de manière légale et, dans cette optique, pratiquer du web scraping peut s'avérer ultra risqué.
En France, la loi est en faveur des entreprises jugeant opportun de se protéger contre le web scraping. L'article 323-3 du Code pénal énonce que le fait d'extraire frauduleusement des données d'un système de traitement automatisé pourrait être puni de cinq ans d'emprisonnement et de 150 000 € d'amende. Toutefois, le terme « frauduleux » mériterait d'être précisé. La société Leboncoin.fr a mal perçu de voir ses annonces immobilières faire l'objet d'extractions de données par un site concurrent et la justice lui a donné raison, ce qui a même été confirmé lors d'un appel jugé le 2 février 2021.
Moralité : avant de se lancer dans une procédure de web scraping, il est essentiel de vérifier ce facteur. Et quoi qu'il en soit, masquer son adresse IP est fortement recommandé.














 donnent la liste des métiers considérés comme les plus ennuyeux. © stokkete, Adobe Stock")

