

Des chercheurs de chez Microsoft ont publié Visual ChatGPT, une version plus évoluée du chatbot capable de comprendre le contenu des images, ainsi que de générer ou d’éditer des images à la demande.
au sommaire
L'un des principaux points faibles de l'intelligence artificielle conversationnelle ChatGPTChatGPT est qu'elle est limitée au texte uniquement. Pour résoudre ce problème, des chercheurs de chez MicrosoftMicrosoft viennent de publier une nouvelle version de ChatGPT baptisée Visual ChatGPT. Dans l’article associé, ils expliquent comment ils ont réussi à intégrer la prise en charge des images dans ChatGPT sans toucher à l'IA elle-même.
Plutôt que de reconstruire complètement ChatGPT pour prendre en charge différentes modalités (audio, images, vidéos...)), ils ont décidé de s'appuyer sur les modèles de fondation visuels (VFM) préexistants, comme Stable Diffusion, BLIP, Transformers, Maskformer et ControlNet. Autrement dit, des IA déjà capables de comprendre ou de générer des images.

Un gestionnaire de requêtes
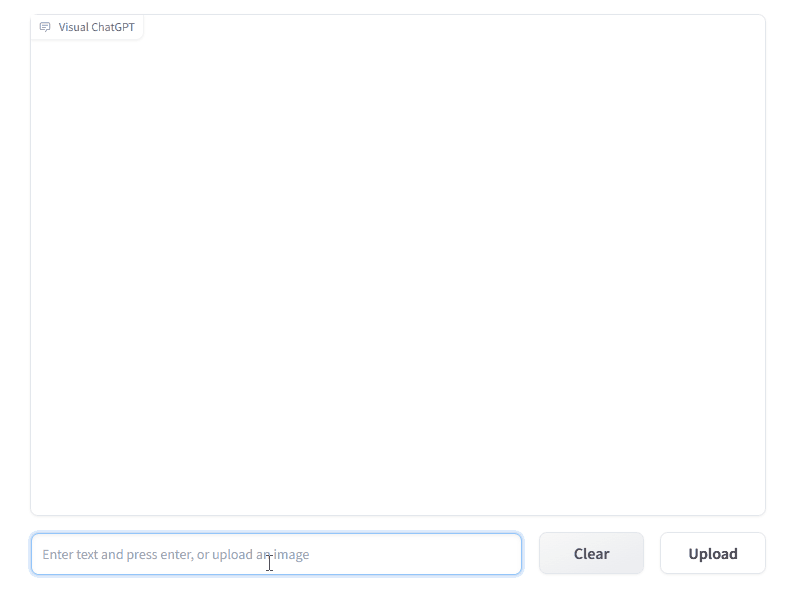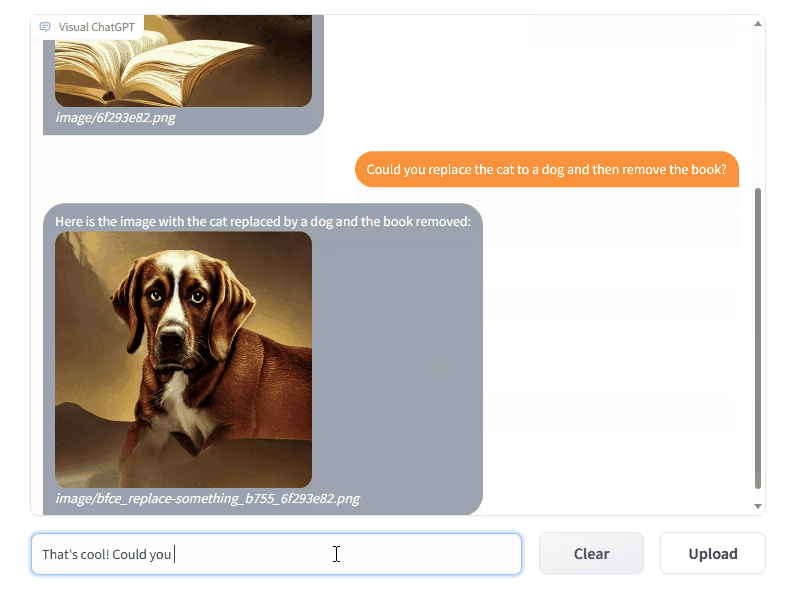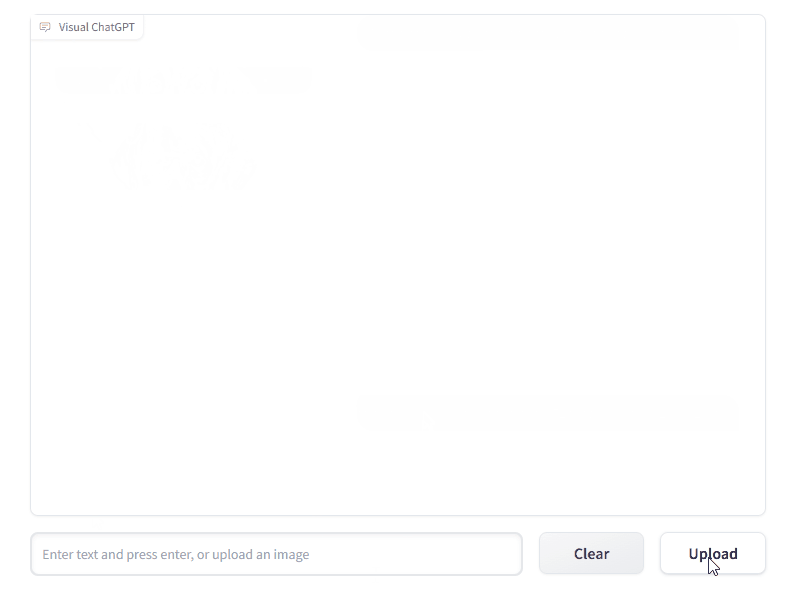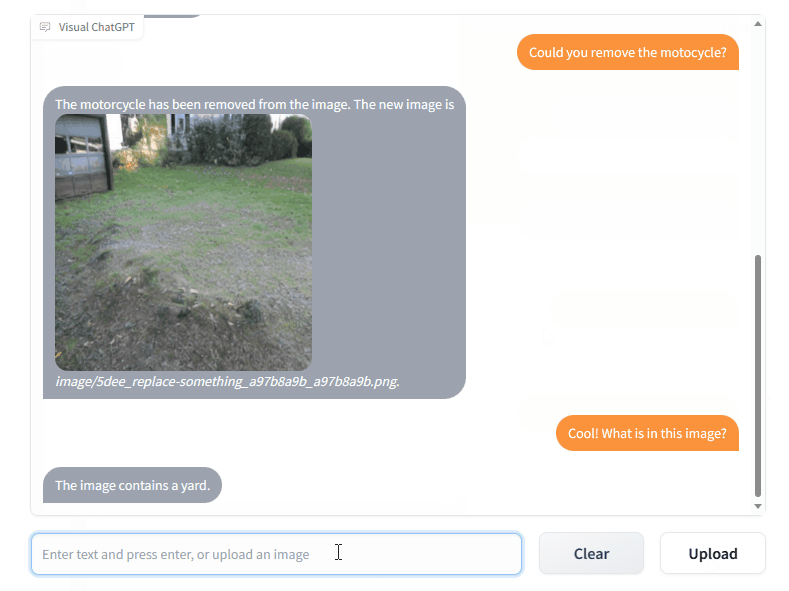
Le module central de Visual ChatGPT est le gestionnaire de requêtes (Prompt Manager). Celui-ci s'occupe de traduire les requêtes de l'utilisateur et de les transférer vers ChatGPT ou une VFM, avec un processus qui peut se dérouler en de multiples étapes internes avant d'aboutir à une réponse. Le résultat est très surprenant. Après avoir envoyé au chatbot une photo, vous pouvez lui demander d'identifier un élément qui s'y trouve (« quelle est la couleurcouleur de la motomoto ? ») ou encore d'éditer l'image (« supprime la moto »). Dans un des exemples, un utilisateur envoie un schéma très basique d'une pomme et d'un verre, et demande à l'IA de l'améliorer. Visual ChatGPT répond avec une image photoréaliste d'une pomme et d'un verre sur une table, placés de la même manière que sur le schéma.
Selon les chercheurs, l'avantage de cette approche est qu'il est très facile d'intégrer de nouveaux modèles visuels. Ils ont partagé leur code sur GitHub, mais il n'existe pas pour l'instant d'interface Web. Pour pouvoir le tester, il faut donc être en mesure de le compiler soi-même...






 ? © phonlamaiphoto, Adobe Stock")







 produits par la photosynthèse sont dégradés par les micro-organismes présents dans le sol, qui produisent du CO2, des protons (H+) et des électrons (e-) captés par l'anode, générant ainsi un courant électrique. © ESA")

, responsables de quelque 40 000 décès en France. © Ponchita, Adobe Stock")




")


