

au sommaire
Montre-moi tes tweets et je te dirai si tu as bu... Dans une étude scientifique parue cette semaine (à lire sur arXiv), une équipe de chercheurs de l'université de Rochester (État de New York, aux États-Unis) explique comment elle a entraîné un algorithme d'apprentissage automatique (machine learning) à identifier des messages postés sur TwitterTwitter par des personnes ayant consommé de l'alcool. Plus troublant encore, le programme parvient même à déterminer si elles boivent chez elles ou à l'extérieur.
Pour parvenir à ce résultat, les spécialistes ont commencé par collecter des messages Twitter publics géolocalisés émis entre janvier et juillet 2014 dans la ville de New York et le Comté de Monroe. Ils ont appliqué une première série de filtres en ne retenant que les tweets contenant les mots-clés « alcool », « fête », « bière », « saoul », « bourré », etc.
Puis, les chercheurs ont fait appel à la plateforme de crowdsourcing AmazonAmazon Mechanical Turk qui rémunère des internautes pour pratiquer des travaux d'analyse de données. Chaque tweet a été étudié par trois personnes qui devaient dire si selon elles le message faisant bien référence à l'alcoolalcool, si l'auteur était le consommateur et si oui est-ce qu'il était en train de boire au moment où il envoyait ce tweet.

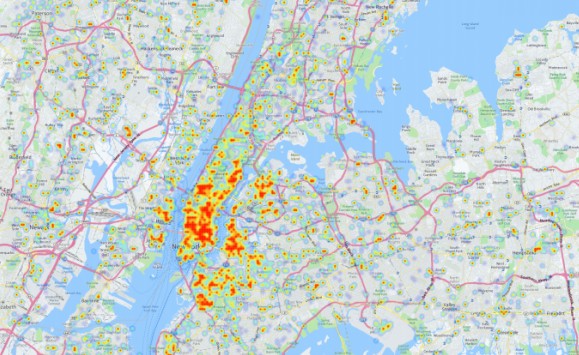
Voici la carte qui présente les zones de consommation d’alcool en fonction des tweets émis. L’intensité colorimétrique est calculée selon le volume de messages associés à l’alcool. Dans la ville de New York, on constate par exemple que les zones les plus denses se trouvent dans la partie basse de Manhattan. © University of Rochester
Des mots-clés qui en disent long
De ce processus est sortie une base de données de 11.000 messages qui ont servi à entraîner l'algorithme à repérer des tweets liés à l'alcool. Cependant, l'équipe de Rochester est allée plus loin en cherchant comment elle pourrait exploiter ces données pour savoir où se trouvaient les personnes et à quel moment elles étaient en train de boire. Une nouvelle liste de mots-clés contenant des termes tels que « maison », « enfin rentré », « canapé », « tv », « douche », « bain », etc. a permis de resserrer les résultats. L'algorithme a ensuite recoupé ces informations avec d'autres indicateurs comme la géolocalisation du dernier message de la journée envoyé par une personne, le pourcentage de tweets émanant d'une zone géographique précise...
Résultat, les chercheurs assurent qu'ils peuvent déterminer le lieu de résidence d'une personne à 100 mètres près avec une fiabilité de 80 %. Ils ont également réussi à corréler la densité de tweets envoyés sous l'emprise de l'alcool avec la densité des points de vente d'alcool (barsbars, restaurants, revendeurs). L'intérêt de cette technique est qu'elle est rapide et peu onéreuse comparée aux méthodes de sondage de terrain qui sont habituellement employées.
Surtout, le fait de travailler avec de l'apprentissage machine ouvre la possibilité de faire un tel suivi en temps réel. Et l'on peut imaginer qu'il soit possible de faire évoluer l'échelle de l'algorithme afin qu'il puisse travailler sur des zones géographiques plus larges.
Selon les auteurs de l'étude, cette méthode pourrait avoir un impact significatif sur la compréhension et la manière de répondre aux questions de santé publique liées à l'alcool et aux problématiques qui en découlent. Ce type d'information pourrait être croisé avec d'autres données socio-économiques qui permettraient de contextualiser plus finement la consommation d’alcool afin d'apporter des mesures préventives mieux ciblées. Les chercheurs indiquent par ailleurs que leur outil d'apprentissage automatique peut s'appliquer à d'autres comportements et « états latentslatents ».

















. © Dall.E")






