
au sommaire


Les ingénieurs de Fujitsu ont élaboré une nouvelle technique de synthèse vocale qui permet d’adapter le ton aux circonstances. Finies les voix synthétiques monocordes. Selon le contexte, la voix artificielle pourra adapter le ton selon qu’il y ait une urgence, un problème ou pour se faire entendre distinctement dans un environnement bruyant. Le système pourra également permettre de personnaliser les voix pour les rendre plus attrayantes, ce qui serait agréable notamment pour les assistants vocaux que l’on trouve dans les GPS et les smartphones. © Fujitsu Laboratories
Les voix de synthèse sont désormais très présentes dans notre quotidien, qu'il s'agisse de celles que l'on entend dans les transports en commun, certains distributeurs automatiques, les services téléphoniques, les GPS des automobilesautomobiles ou encore les assistants vocaux des smartphones. Mais force est de constater qu'elles sont toujours aussi monocordes et impersonnelles. Le résultat est que l'information diffusée par ce biais n'est pas assez adaptée au contexte. De surcroît, faire évoluer une voix de synthèse nécessite le traitement d'un gros volumevolume de données, ce qui prend du temps.
Fujitsu Laboratories a travaillé sur ce sujet et conçu une nouvelle technologie qui permet de créer des voix de synthèse adaptées aux circonstances dans lesquelles elles sont utilisées. « La technologie de synthèse vocale actuelle est capable de traiter une grande variété de textes, mais d'une voix monocorde. Il y a un besoin d'une synthèse vocale qui soit en mesure de transmettre le texte parlé aux auditeurs selon les circonstances afin de le rendre facile à comprendre », explique l'entreprise japonaise dans son communiqué.
Voix de synthèse qui s’adapte au contexte
Pour rendre le processus de synthèse plus polyvalent, les ingénieurs de Fujitsu ont utilisé une méthode qui consiste à isoler et à convertir en paramètres les caractéristiques du phrasé d'un discours telles que l'intonation, la clarté ou les pauses. Ces paramètres sont stockés dans une base de données et analysés par un algorithme qui utilise l'apprentissage machine pour que le ton de la voix soit approprié à la situation. Une voix synthétique pourra ainsi prendre un ton alarmé en cas d'urgence ou un ton clair et facile à entendre dans un environnement bruyant.
 enregistre une voix. Celle-ci est analysée pour extraire ses caractéristiques (ton, clarté, pauses, etc.) qui sont transformées en paramètres qui vont alimenter une base de données (<em>parameter database</em>). Dans une situation d’urgence (<em>emergency</em>), la synthèse vocale est traitée par un algorithme basé sur l’apprentissage machine qui va ajuster le ton de la voix de synthèse (<em>synthesized voice</em>) au contexte. © Fujitsu Laboratories")
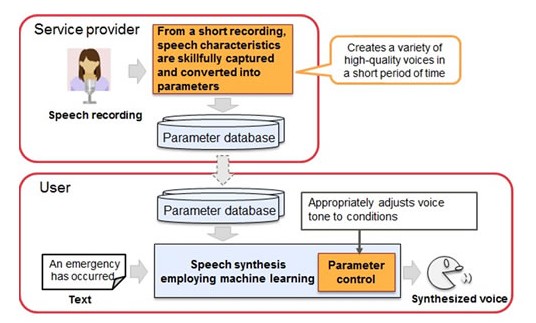
Le principe du système de synthèse vocale mis au point par Fujitsu. Un fournisseur de service (service provider) enregistre une voix. Celle-ci est analysée pour extraire ses caractéristiques (ton, clarté, pauses, etc.) qui sont transformées en paramètres qui vont alimenter une base de données (parameter database). Dans une situation d’urgence (emergency), la synthèse vocale est traitée par un algorithme basé sur l’apprentissage machine qui va ajuster le ton de la voix de synthèse (synthesized voice) au contexte. © Fujitsu Laboratories
L'intérêt est qu'un système vocal pourra s'adapter en temps réel. Dans les usines par exemple, les machines qui utilisent des voix de synthèse pour informer les opérateurs pourront moduler l'intonation de leurs messages : calme et normal en opération de routine, préoccupée en cas d'erreur de manipulation ou bien agitée devant l'urgence. Les autorités municipales pourraient aussi se servir d'un tel système pour diffuser des messages à la population afin de faire de la préventionprévention en cas de situation à risque (événement climatique, tremblement de terretremblement de terre, tsunamitsunami, etc.). Une voix posée et clairement audible serait diffusée pour prodiguer des recommandations tandis qu'en cas de catastrophe, le ton pourrait être adapté en fonction de l'urgence.
Premières applications pour le courant de l’année 2014
Par ailleurs, la technologie de Fujitsu présente l'avantage de nécessiter seulement une petite quantité d'échantillons sonores et de réduire d'environ un tiers le temps nécessaire pour créer une voix synthétique. Il serait ainsi plus aisé de personnaliser un service vocal et de le mettre à jour en fonction des besoins. Fujitsu pense que son innovation permettrait d'adapter les voix de synthèse selon les préférences des utilisateurs, en les rendant plus attachantes ou typées selon les usages. De quoi par exemple personnaliser un peu plus un assistant vocal comme le Siri d'Apple, ou bien la voix d'un système de guidage GPS.
Les ingénieurs voient même encore un peu plus loin en imaginant que le système pourrait servir dans un cadre médical. Une personne malade susceptible de devenir aphone pourrait enregistrer sa voix à l'avance pour communiquer avec son entourage en se servant de son double vocal synthétisé. Fujitsu Laboratories indique qu'il faut encore peaufiner la technologie, et l'entreprise pense proposer les premières applicationsapplications dans le courant de son exercice fiscal de 2014.



 Le magicien d'Oz, de L. Frank Baum. © The York Project, domaine public")


















")
