, c'est-à-dire du « calcul à haute performance » avec des superordinateurs. Sans lui, la découverte du boson de Brout-Englert-Higgs aurait été impossible. © Sophia Elizabeth Bennett, Cern")
, c'est-à-dire du « calcul à haute performance » avec des superordinateurs. Sans lui, la découverte du boson de Brout-Englert-Higgs aurait été impossible. © Sophia Elizabeth Bennett, Cern")
Les techniques de compression de données sont partout : elles permettent de réduire la taille des fichiers musicaux et d'images mais aussi d'effectuer du calcul à haute performance. Le Français Olivier Thomine, un jeune numéricien, vient d'élaborer un nouvel algorithme de compression prometteur qui devrait impacter tous ces domaines. Rencontre.
au sommaire
Dans ses célèbres Leçons sur l’informatique, le prix Nobel de physiquephysique Richard Feynman ne fait pas qu'introduire le lecteur à la théorie des machines de Turing et à celle des ordinateurs quantiquesordinateurs quantiques. Il y expose aussi les bases de la théorie de l’information de Claude Shannon ainsi que celles de la théorie du codage. Ces deux dernières théories fascinantes sont liées entre elles et sont essentielles pour la conception de systèmes manipulant de l'information de façon de plus en plus efficace.
Qu'il s'agisse de faire de longs calculs sur ordinateur ou encore de transmettre et de stocker de l'information, comme des images ou du son, on a tout intérêt à minimiser la longueur des données que l'on manipule et qui contiennent cette information. Se pose alors le problème du codage.
L'un des exemples les plus anciens est peut-être celui de l'utilisation des chiffres indiens à la place des chiffres romains. Ils ont permis d'effectuer des calculs de façon plus efficace. Un autre exemple, plus récent, est la mise au point du code MorseMorse en 1838 : l'une des idées de base était de coder les caractères les plus fréquents dans des messages avec le moins de signaux possible, sous forme d'assemblages de points et de tirets. Inversement, on utilise les assemblages les plus longs pour les caractères qui reviennent le plus rarement. Ainsi, le « e », qui apparaît fréquemment est codé par un simple point alors que le « x » est codé avec quatre symboles. Cela permet donc de compresser la longueur des messages.
 est un ingénieur en génie électrique et mathématicien américain. Il est l'un des pères fondateurs de la théorie de l'information qu’il développa largement du fait de ses travaux en cryptographie pendant la seconde guerre mondiale. Il était chargé de localiser de manière automatique dans le code ennemi les parties signifiantes cachées au milieu du brouillage. Il rencontra à ce moment Alan Turing, qui travaillait lui aussi sur la cryptographie. Ses découvertes furent exposées durant la période d'après-guerre dans un célèbre article, <em>A Mathematical Theory of Communications</em> (1948). On doit à Shannon la mise en évidence d’un lien très profond entre la notion d’entropie et celle d’information, ce qui a conduit aux méthodes dites « d'entropie maximale » utilisées notamment pour faire de la reconnaissance automatique des caractères, de l'apprentissage automatique et qui sont aussi employées dans le cadre de l’imagerie médicale. © <em>MIT museum</em>")

La compression des données, une nécessité pour l'informatique
L'avènement des télécommunications au XXe siècle, ainsi que la montée en puissance des tâches demandées aux ordinateurs, a conduit les ingénieurs et les mathématiciensmathématiciens à étudier de près des techniques similaires de plus en plus élaborées pour compresser les données. On comprend facilement, par exemple, qu'au temps où les ordinateurs ne disposaient pas de beaucoup de mémoire vivemémoire vive ou morte, on avait tout intérêt à pouvoir écrire des programmes ou à stocker des données sous la forme la plus courte possible. Il en est de même lorsque l'on veut effectuer des calculs ou transmettre des informations. Il n'est évidemment pas question que le temps pris pour le faire dépasse plusieurs mois ou encore plusieurs années, voire des siècles.
Un des plus célèbres codes de compression de données a été découvert par David Albert HuffmanHuffman alors qu'il était en thèse au MIT (Massachusetts Institute of Technology) au début des années 1950. Le principe de ce code est simple à comprendre. Donnons-nous 100 caractères possibles qui peuvent être des lettres de l'alphabet, des chiffres, d'autres symboles comme des points-virgules, des parenthèses, etc.
Avec eux, on pourrait former 10010 expressions longues de 10 symboles. Cependant, en réalité, on utilise en général un nombre bien moins important de combinaisons pour coder un texte ou un programme (tghyul !@_} ne correspond à rien, par exemple). L'idée de Huffman est que, pour tout texte source donné, il faut d'abord analyser les fréquences d'apparition des mots ou des assemblages de caractères. On peut ensuite associer à ces assemblages des nombres en binairenombres en binaire qui sont d'autant moins longs qu'ils sont les plus fréquents.
Il est possible d'effectuer ainsi une compression sans pertes de fichiers contenant des textes ou des programmes. Pour des images et des sons, on peut utiliser d'autres algorithmes qui, au prix d'une certaine perte d'information acceptable pour un œilœil ou une oreille, permettent de compresser l'information.
 fut un pionnier de la compression de données dans le domaine de l'informatique. On lui doit le codage de Huffman, utilisé par exemple avec des fichiers en MP3 et en JPeg. © Don Harris")

De nos jours, on peut compresser de 50 % des fichiers textes, de 80 % des images fixes et de 95 % des films selon la qualité voulue. Le MP3 et le JPeg sont utilisés pour la compression avec perte, respectivement, des fichiers musicaux et d'images. Il n'est pas exagéré de dire que les techniques de compression des données sont désormais omniprésentes et vitales, aussi bien dans la vie quotidienne, avec les DVD, nos téléphones et ordinateurs portables, que pour l'imagerie en médecine et en astronomie (elles rendent par exemple possible l'obtention des images de la surface de PlutonPluton ou la recherche de nouvelles particules dans les détecteurs du LHCLHC).
Une technique de compression pour le calcul à haute performance
Toute nouvelle méthode de compression des données qui serait plus efficace que les autres, au moins dans certains cas, est donc importante, aussi bien pour la recherche fondamentale que pour l'industrie.
OlivierOlivier Thomine, un jeune numéricien, a justement trouvé un nouvel algorithme prometteur de compression alors qu'il était en postdoc au CEA (Commissariat à l'énergieénergie atomique et aux énergies alternatives). Il a notamment travaillé sur la simulation numériquesimulation numérique des plasmas tels ceux que l'on rencontrera dans le réacteur d'IterIter. Les membres de Futura-Sciences le connaissent bien puisqu'il est un des modérateurs actifs du forum. Nous avons donc demandé à Olivier Thomine de nous expliquer l'enjeu de sa découverte.


Futura-Sciences : Il existe deux types d’algorithmes de compression : ceux avec perte et ceux sans perte. À quelle famille votre nouvel algorithme appartient-il ?
Olivier Thomine : Cela peut paraître surprenant, puisqu'il s'applique notamment aux sons, aux photos et à la vidéo, mais il s'agit d'un algorithme qui permet de faire de la compression sans perte. En fait, ce n'est pas le premier capable d'une telle performance. Il existe par exemple depuis 1984 l'algorithme LZW, pour Lempel-Ziv-Welch, qui, bien qu'étant un algorithme de compression de données sans perte est utilisé pour les fichiers d'images Gif et Tiff ainsi que les fichiers audio en MOD pour la musique.
Futura-Sciences : Peut-on se faire une idée de l’efficacité de ce nouvel algorithme ?
Olivier Thomine : Oui, il permet de compresser les données beaucoup plus rapidement que le LZW et, pour des tests que j'ai effectués avec des fichiers de données concernant des capteurscapteurs de rayonnement mais aussi des capteurs cardiaques, il est quatre fois plus rapide que les méthodes usuelles.
, c'est-à-dire le « calcul à haute performance » avec des superordinateurs. Au centre, les méthodes standard et, à droite, la nouvelle méthode. © Oliver Thomine")
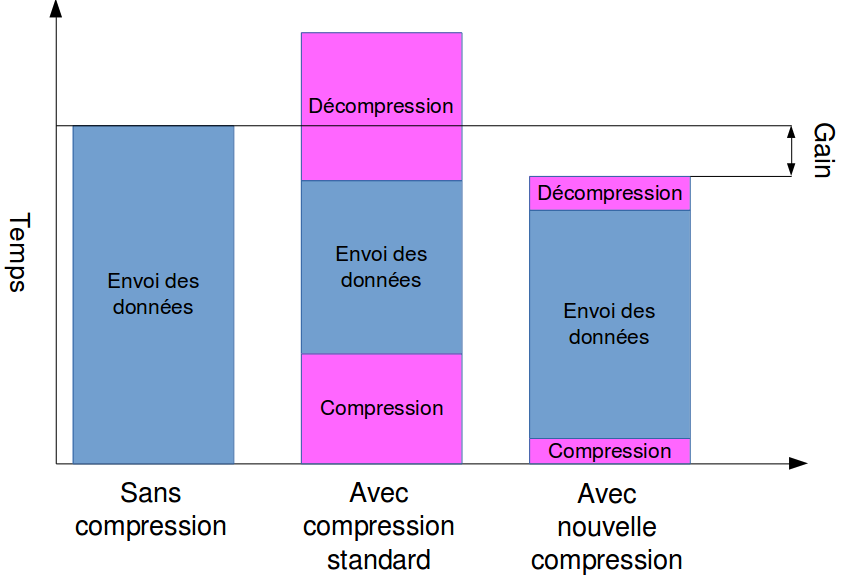
Futura-Sciences : Dans quels domaines est-il susceptible de faire la différence avec les autres méthodes de compression ?
Olivier Thomine : Il est probable que presque tous les domaines scientifiques vont être impactés, du médical au nucléaire en passant par les transmissions satellitaires et avec des sondes spatiales. Mais le domaine où l'algorithme devrait vraiment être très utile, c'est celui du HPC (High-Performance Computing) ou, en français, le « calcul à haute performance » avec des superordinateurssuperordinateurs. La raison en est simple, c'est justement parce que j'essayais d'améliorer la vitessevitesse de calcul de simulations numériques impliquées dans la physique des plasmas dans le cadre du projet Tore-Supra, lors de mon postdoc à Cadarache, que j'ai élaboré ce nouvel algorithme de compression.
Le HPC est vraiment partout de nos jours et il est devenu un outil essentiel de la recherche scientifique, technologique et industrielle. Il intervient par exemple lorsque l'on veut modéliser des crashs d'avions ou de voituresvoitures, des moléculesmolécules biologiques d'intérêt pharmaceutique, le climatclimat ou encore la formation et l'évolution des galaxiesgalaxies et des étoilesétoiles. Il s'agit à chaque fois de pouvoir exécuter plusieurs milliards d'opérations à la seconde pour modéliser des phénomènes complexes ainsi que pour traiter ou qualifier rapidement de gros volumesvolumes de données comme celles obtenues dans les détecteurs du LHC lors des collisions de faisceaux de protonsprotons.
Pour vous donner un exemple précis, il y a actuellement un laboratoire en partenariat avec le CEA qui fait des tests de toxicitétoxicité avec des capteurs sur des matrices de cellules cardiaques. Il y a tellement de données qu'on n'arrive plus à les transférer efficacement à des clusters de calculateurs afin de les éplucher. Avec le nouvel algorithme, ils pourront le faire.









. © Google")
 n’est pas une fatalité, pour peu que l’on ait pris quelques précautions préalables. © Alex, Fotolia")













