




au sommaire


La morale actuelle : deux techniques complémentaires valent mieux qu'une !
Après avoir fait faire un bond en avant à la traduction automatique, la méthode statistique bute elle aussi sur une limite : elle ne permet pas de traduire des expressions jamais ou rarement rencontrées. Pour l'améliorer, la seule solution connue aujourd'hui est de la compléter d'une classique analyse linguistique, avec ses règles propres à chaque langue. Un panachage qui fait ses preuves.
La méthode statistique ignore toute règle et ne peut donc effectuer aucune généralisation. Si une traduction est trouvée pour un mot au singulier seulement, le logiciellogiciel ne saura pas le mettre au pluriel. Ce handicap est contourné par l'énorme masse de données que peut traiter un ordinateurordinateur ayant accès aux serveursserveurs d'une entreprise ou au Web. Mais contourné seulement. Ce qui n'a pas déjà été traduit ne pourra pas l'être. De plus, on l'a vu avec l'exemple des phrases courtes, la méthode statistique implique de prendre en compte le contexte pour choisir parmi plusieurs traductions possibles. Hors contexte, la méthode statistique, sans règle, ne peut plus avancer...
Il est clair qu'une limite est atteinte. La meilleure démonstration de l'existence d'un obstacle est le service de GoogleGoogle. L'entreprise américaine a engagé des moyens importants et dispose aujourd'hui d'une méthode rôdée. La preuve est la rapiditérapidité avec laquelle sont apparues de nouvelles langues après les premiers tours de roues entre les langues les plus répandues. La méthode de Google est manifestement bien au point mais elle ne progresse pas en qualité. « Si la puissance informatique était suffisante pour aller plus loin, estime Jean Senellart, directeur de la R&D de Systran, par exemple en augmentant le nombre de serveurs, Google aurait déjà mis en œuvre les moyens nécessaires. Mais il ne l'a pas fait. »
Devant la phrase il fait chaud, une analyse linguistique détaillera la construction et détectera un pronom (PRO), un verbe (GV, groupe verbal) et un adverbe (ADV). Elle cherchera ensuite la règle correspondant à ce cas. Ici, trois pourrait convenir. Si la phrase était il fait le beau, la règle serait V(faire;objet→GN(beau)), où V désigne une règle concernant un verbe et GN un groupe nominal. Si la phrase était il se fait beau, la bonne régle serait V(faire;réfléchi;MODIFIEUR=beau), modifieur désignant un mot modifiant le sens du verbe, ici l'adverbe. Avec la phrase proposée, la bonne règle sera V(faire;sujet→"il";MODIFIEUR=chaud,froid,gris,mauvais,beau). En anglais, cette construction se traduit par the weather is MODIFIER (le dernier terme désignant le modifieur, traduit en anglais). © Systran
Les bienfaits des règles
Il semble clair pour tout le monde aujourd'hui que le futur proche de la traduction automatique passe par une approche mixte, mêlant la classique linguistique, avec ses règles, et la statistique, pour effectuer dans une seconde phase une validation par le corpus. Dans un premier temps, l'application des règles permet pour chaque mot ou groupe de mots de déterminer différentes traductions possibles. Les règles permettent de généraliser, c'est-à-dire de traduire une phrase jamais rencontrée en construisant une forme jamais produite. Dans la plupart des cas, plusieurs solutions sont trouvées. L'approche statistique vient alors en appui pour vérifier comment les précédents traducteurs ont choisi parmi elles. En somme, l'analyse linguistique limite le nombre d'erreurs dans les cas où la statistique n'est pas efficace tandis que celle-ci réduit le travail de la première.
 est traduit par la version 6 du logiciel de Systran, avec une méthode linguistique, et par la version 7, qui ajoute une authentification par le corpus de données (méthode statistique). Les expressions soulignées en rouge sont celles qui diffèrent entre les deux traductions. Dans la colonne de droite figure la bonne traduction. © Systran")
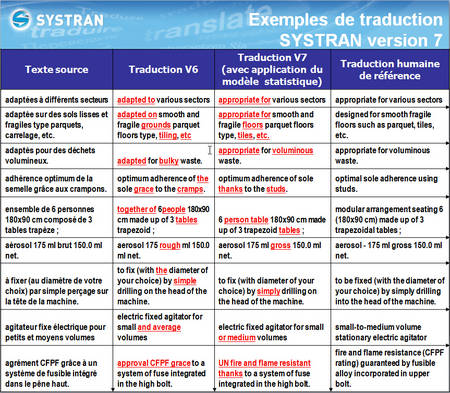
Un exemple réel de panachage des méthodes linguistique et statistique, pour la traduction d'un catalogue de produits. Le texte source (colonne de gauche) est traduit par la version 6 du logiciel de Systran, avec une méthode linguistique, et par la version 7, qui ajoute une authentification par le corpus de données (méthode statistique). Les expressions soulignées en rouge sont celles qui diffèrent entre les deux traductions. Dans la colonne de droite figure la bonne traduction. © Systran
La méthode mixte a un autre avantage direct, et très matériel, par rapport à une solution purement statistique. La taille de la base de donnéesbase de données nécessaire est considérablement réduite. Une dizaine de milliers de règles suffisent alors à l'intérieur d'un domaine spécifique (par exemple au sein d'une entreprise). Mais surtout, le cumul des deux techniques améliore incontestablement la qualité de la traduction.
Pour la traduction destinée à la recherche d'informations, qui ne délivre qu'une syntaxe approximative, ce panachage de la linguistique et de la statistique donne aujourd'hui les meilleurs résultats.
Mais une intervention humaine reste indispensable pour aller jusqu'à la réalisation d'un document définitif. Dans les versions de ce logiciel (réalisé par Systran) destinées aux entreprises, le système passe par une phase d'apprentissage, qui consiste à indexer les documents déjà traduits. L'entreprise devra en définir la liste, au sein de laquelle le logiciel bâtira son index, par auto-apprentissage.
Un traducteur de chair et d'os interviendra éventuellement pour finaliser la version définitive. C'est ainsi que pourront être corrigées des erreurs mais cette interaction peut aussi servir à prendre en compte des habitudes maison (termes préférés, sigles...).
Avec ce triple panachage mêlant règles linguistiques, vérification statistique et peaufinage humain, la traduction automatique, qui n'est donc alors qu'une traduction assistée, peut désormais donner d'excellents résultats.








